表現
ボイス:人格の音声化
声は、人格が身体を持つ最初の瞬間である
Chapter 5までで、Mumonの生成パイプラインは、「何を言うか」「どう言うか」「なぜその人格らしいのか」を構造として定義してきました。System1が応答の起点となる温度を立ち上げ、System2がそれを制約・記憶・人格に接地させる。こうして、テキストとしての応答は完成します。
けれども、その段階でまだ欠けているものがあります。
ユーザーが受け取っているのは、まだ文章であって、体験ではないということです。
画面に「大丈夫だよ」と文字で表示されるのと、少し間を取りながら低く落ち着いた声で「......大丈夫だよ」と語りかけられるのとでは、体験はまったく異なります。私たちは言葉の意味だけでなく、声の高さ、速度、間、息づかいといった韻律からも相手の感情を読んでいます [65]。
だから、声は単なる出力形式の違いではありません。
内部で計算された感情の温度や人格の質感を、ユーザーの身体感覚へ直接届ける最初のチャネルなのです。ここで初めて、人格は「読むもの」から「感じるもの」へと変わります。
本節が扱うのは、この「人格が身体を持つ最初の瞬間」の設計です。
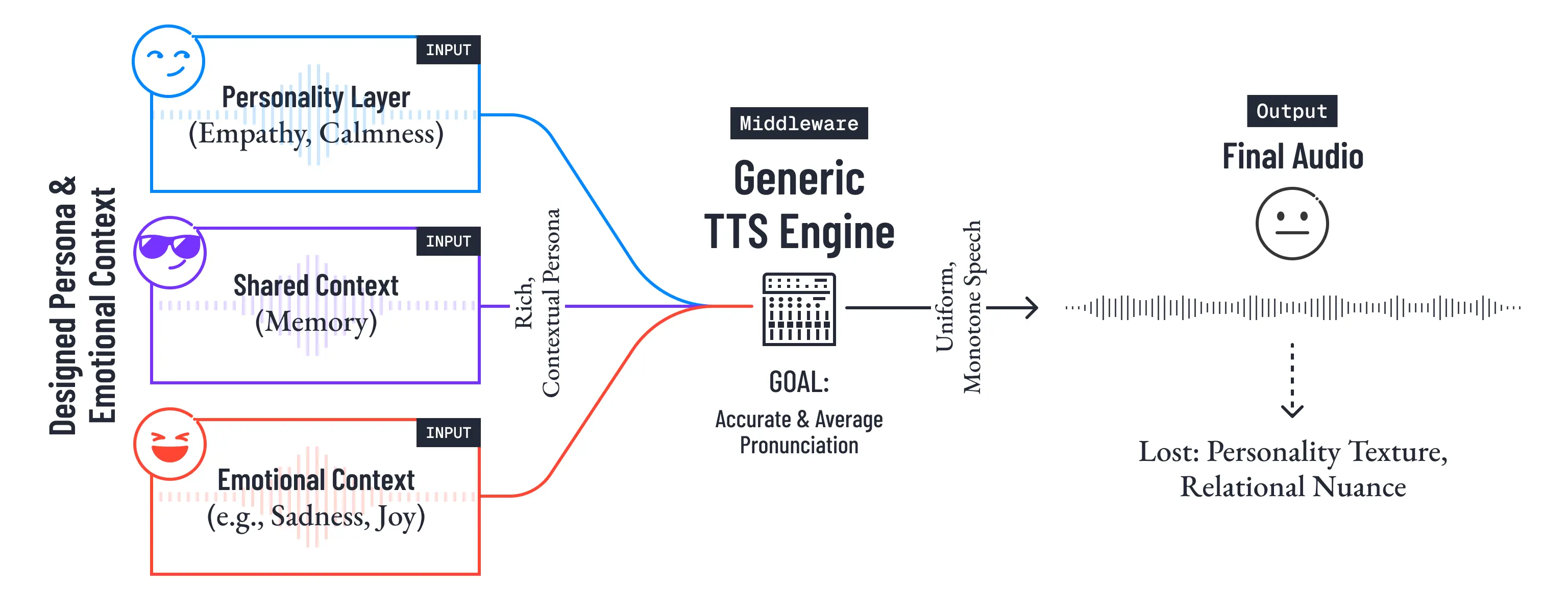
汎用TTSは、人格の温度を最後の出口で平滑化してしまう
従来の音声対話AIの多くは、「どんなテキストを返すか」に大きな注意を払う一方で、最終的な音声化は汎用TTSに委ねています。もちろん、それ自体は合理的です。汎用TTSは安定しており、発音も綺麗で、平均的な品質を確保しやすい。
しかし、そこにはひとつ根本的な問題があります。
汎用TTSが目指しているのは、「正確で平均的に発音すること」であって、テキストに埋め込まれた感情的文脈や人格的距離感を再構成することではない、という点です。
その結果、Chapter 3からChapter 5までで丁寧に設計された「この温度で、この距離感で語りかける」という人格の質感が、音声化の最終段階で均一化されてしまいます。
「......そっか、悲しかったね」という言葉が、ニュースキャスターのような無機質な棒読みに変わった瞬間、それまで積み上げてきた人格の一貫性は、最後の出口で失われます。行動制御層が読み取った感情の温度も、記憶層が引いてきた共有文脈も、人格DBが保持する気質の色合いも、そこで一度平らに均されてしまうのです。
問題は音声技術の精度不足ではありません。
人格の温度を、音声化まで貫通させる設計が欠けていることにあります。
言い換えれば、汎用TTSは「正しく読む」ことには強いが、「その人格として語る」ことには弱い。ここで失われるのは、情報ではなく、関係性の手触りです。
Mumonの音声モデルは、「感情的に聞こえること」に特化している
Mumonにおいても、アーキテクチャ上の最終段階は「生成されたテキストを音声モデルへ渡す」という形を取ります。違いは、そのモデルの中身と、どの方向へ最適化されているかにあります。
汎用TTSが「いかに綺麗に、いかに平均的に発音するか」を学ぶのに対し、Mumonの音声モデルは、「いかに人間らしく、文脈に応じて感情的に聞こえるか」に重心を置いて学習されています。抑揚が大きく、感情の起伏に富んだ音声データを用いた追加学習によって、テキストの背後にある温度や距離感を、声色として再構成することを優先しているのです。
ここで重要なのは、声が「なんとなく雰囲気を足す演出」ではないということです。
前章までで定義した感情の温度、行動制御層の判断、記憶層から引かれた文脈、そして人格DBに保存された気質的傾向。それらは最終的に、ピッチ、速度、音量、間といった韻律へ翻訳されます。感情と音声韻律の対応関係を整理した研究が示してきたように、覚醒度や感情価は、そのまま声の運び方に変換可能な設計変数です [66]。
つまり、ボイスは後から当てはめる化粧ではありません。
人格と感情条件の、聴覚的な帰結なのです。
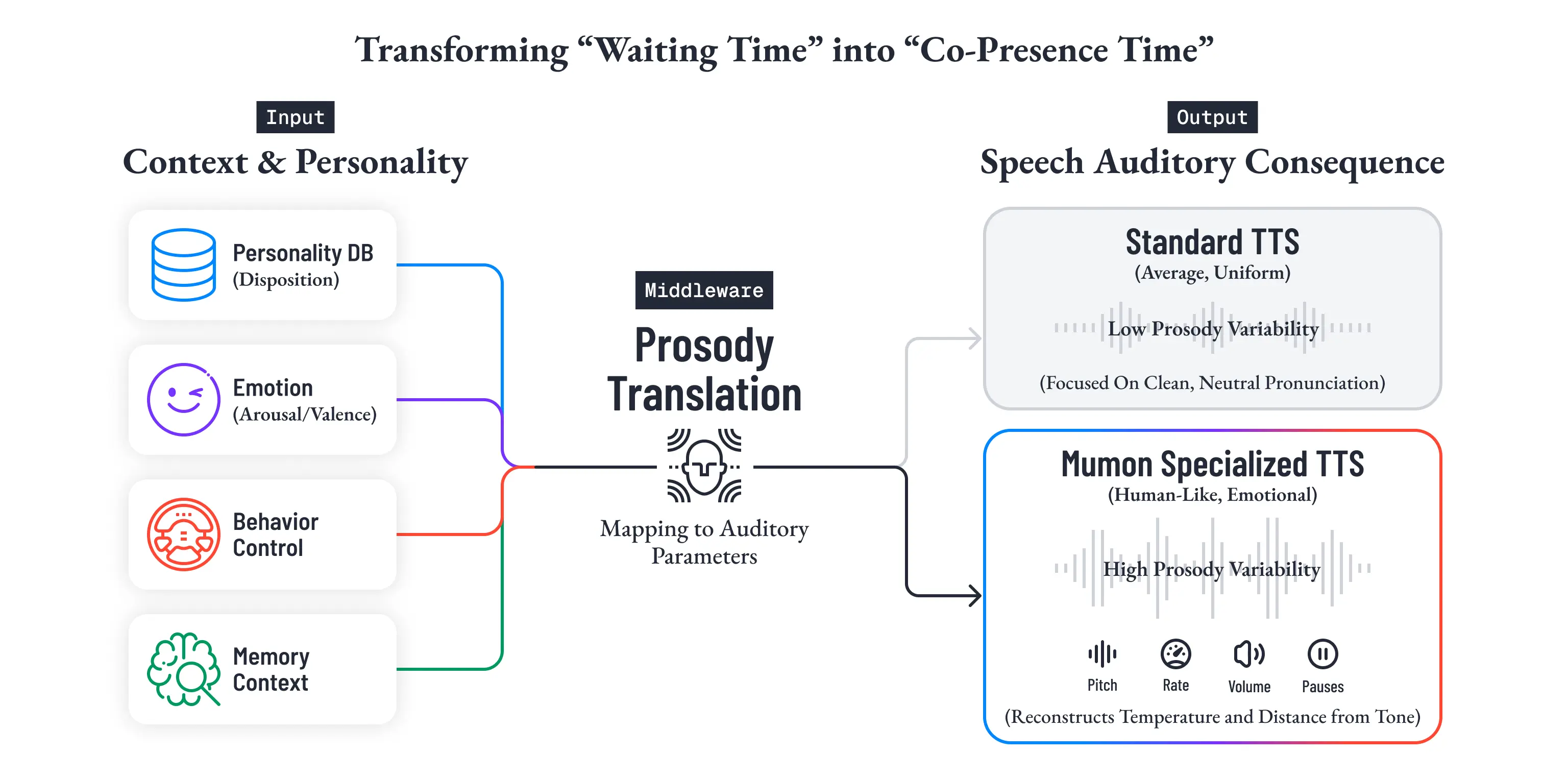
この意味で、Mumonの音声モデルは「テキストを音にする装置」ではありません。むしろ、生成層で完成した人格条件を、ユーザーが身体的に受け取れるかたちへ変換する翻訳機です。同じ「大丈夫だよ」という一文でも、低覚醒で静かな寄り添いとして聞こえるのか、軽すぎる励ましとして聞こえるのかで、体験は根本から変わります。
Mumonが音声モデルの学習目標を「平均的に綺麗」ではなく「感情的に自然」に置いているのは、その差を設計の中心に据えているからです。
没入を決めるのは、音質の忠実度ではなく、応答までの「間」である
ここで、本章全体を貫く設計原則を置く必要があります。HCI研究が繰り返し示しているのは、没入感の鍵を握るのは見た目や音質の精緻さそのものではなく、応答のリアルタイム性だということです。
人は、画面の向こうに社会的な手がかりがあると、それを無意識に「相手」として扱います。しかしその没入は、「どれだけ綺麗に聞こえるか」より前に、「どれだけ自然なテンポで返ってくるか」によって決まります。
人間の会話では、相手の発話が終わってから次に話し始めるまでのギャップは、平均して約200ミリ秒しかありません [67]。AIがここで1秒から2秒沈黙した瞬間、ユーザーは「ああ、相手はシステムだった」と我に返ってしまう。
だから、表現レイヤーで本当に優先すべきなのは fidelity ではなく latency です。
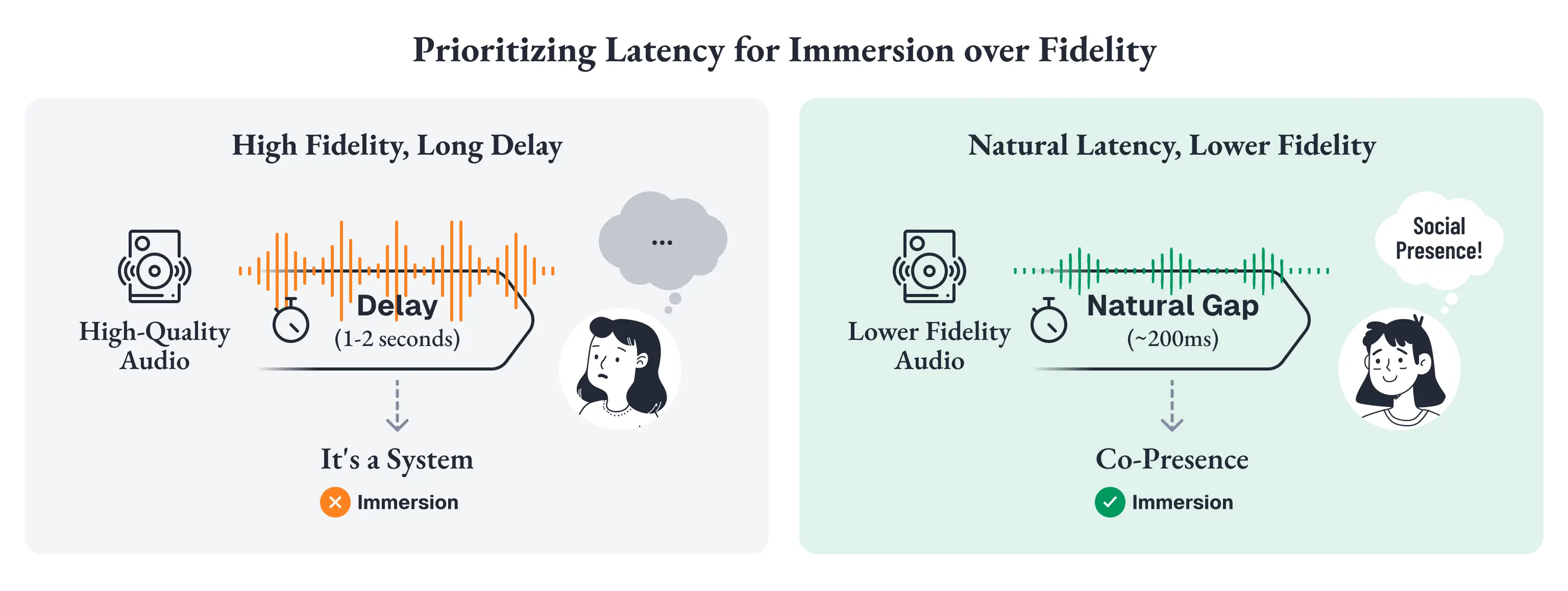
音質の忠実度を上げることよりも、まず「いま返してくれている」と感じられることのほうが、没入にとって決定的なのです。
この原則は、声の設計においてとりわけ重要です。
なぜなら声は、テキストよりもはるかに強く「共在感」をつくるからです。
文字が少し遅れて表示されることと、相槌や短い音声反応が遅れて返ってくることでは、ユーザーの体感はまったく違います。声は、人格の存在を感じさせる最前線にあるからこそ、応答までの「間」がそのまま存在感の強さになるのです。
ここで貫くべき原則は、まさに Latency over Fidelity です。
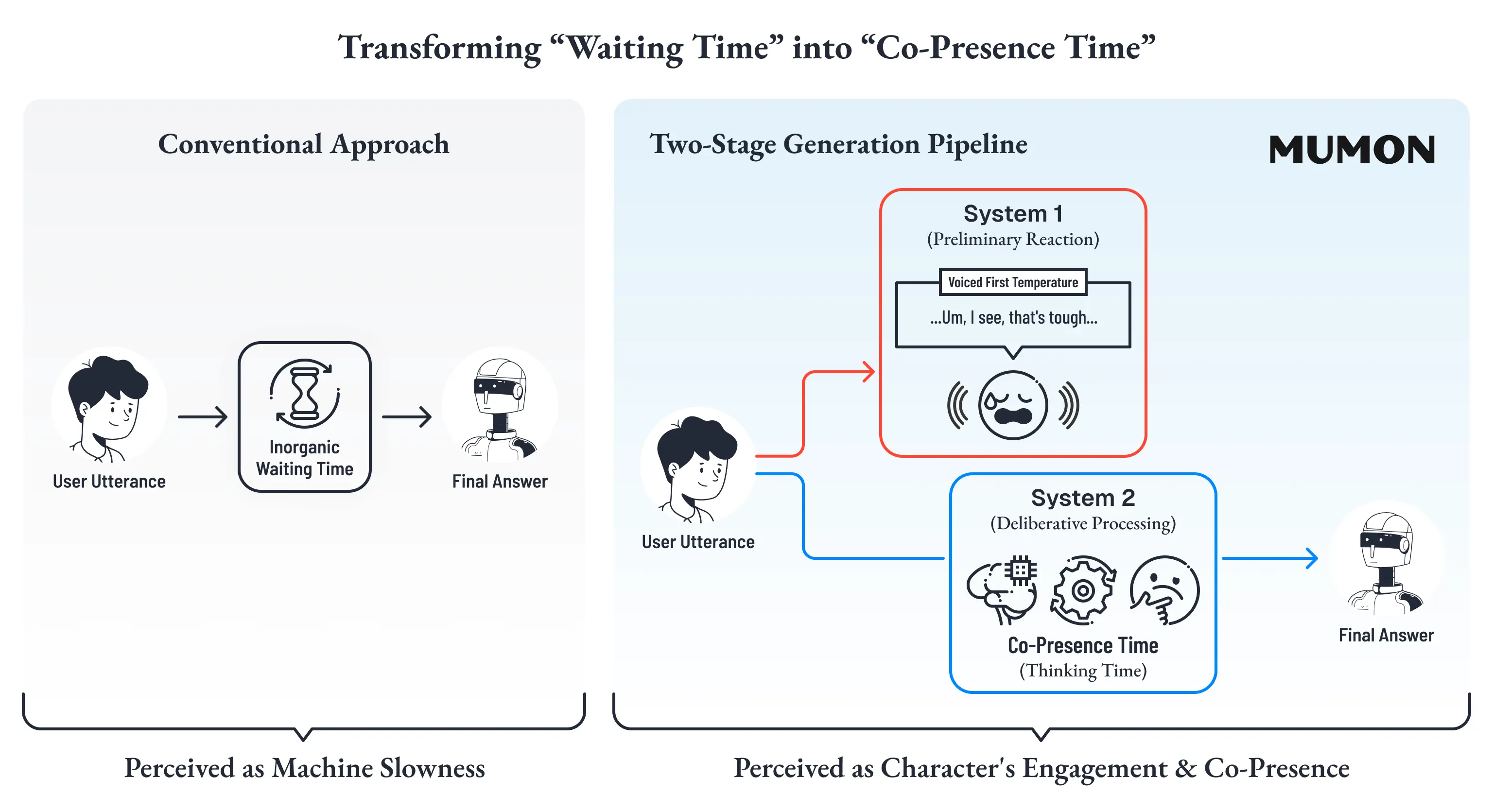
二段階生成パイプラインが、「待ち時間」を「共在の時間」に変える
ここで、前章で設計した System1 / System2 の二段階生成が、表現レイヤーにおいて決定的な意味を持ち始めます。Mumonは、ユーザーが話しかけた直後に、無機質なローディングだけを返すのではありません。System1が立ち上げた短い予備反応を、必要に応じて、先に声として返すことができます。
「うーん」
「そっか」
「......それはつらいね」
こうした短い反応が発話直後に音声として返ることで、System2の熟慮時間は「待たされる時間」ではなく、「このキャラクターがいま考えてくれている時間」へと変わります。
前章で整理した通り、System1の予備反応がつくるのは、情報価値というより共在感でした。その共在感は、テキストで見えるときよりも、声として聞こえたときに初めて、身体的な実感を伴います。
ここで重要なのは、これが単なる演出ではないという点です。
二段階生成パイプラインは、生成品質のためだけにあるのではありません。表現レイヤーにおいては、遅延隠蔽の構造としても機能します。ユーザーの発話直後に、短くても感情に合った反応が返る。その事実があるだけで、裏側で行われている重い熟慮は、「機械の遅さ」ではなく「考えてくれている時間」として解釈されやすくなるのです。
これは、前章で定義した System1 の役割とそのままつながっています。
System1 が生むのは、完成回答ではなく first temperature でした。その温度が、テキストとして見えるだけでなく、声として先に届くことで、ユーザーは「いま向き合われている」という実感を持つことができる。
Chapter 5 の設計が、ここで初めて、表現レイヤーの没入の前提条件として機能し始めるのです。
声のパラメータは、人格DBの構造から導出される
Mumonのボイスは、独立した演出素材ではありません。
前章で定義した人格DBのうち、とくに気質的特性と特徴的適応が、音声表現のテンポ、間、抑揚、安定感に反映されます。たとえば、内向的で思慮深い人格なら、テンポは緩やかになり、間が長くなり、トーンは低めに安定しやすい。外向的で快活な人格なら、テンポが上がり、抑揚の幅も広がりやすい。
さらに、その場の感情状態が高覚醒なら速度や緊張感が増し、低覚醒なら沈静方向へ寄る。こうした韻律の違いは、偶然ではありません。人格と感情の両方から、構造的に導かれるものです。
ここで重要なのは、声もまた「なんとなく合うものを後から当てる」のではなく、人格DBの構造的帰結として設計されるべきだということです。前章で「人格は口調ではなく構造で守る」と定義しました。その原則は、そのままボイスにも貫かれます。
つまり、声の設計とは、テキストを読み上げるための後処理ではなく、人格が外面へ翻訳される最初の出口なのです。
人格DBは、生成の一貫性だけでなく、表現の一貫性をも規定しています。
テキストとして正しいだけでなく、声として聞いても「この人格だ」と感じられること。
その一致が、ユーザーにとっての人格体験を完成させます。
ボイスは、表現レイヤーの入口であり、次節の視覚表現へつながる
Chapter 5 の出力は、あくまでテキストでした。
そのテキストが、ユーザーにとって「人格として感じられる体験」へ変わる最初の瞬間が、声です。
本節で定義したかったのは、4つのことです。
- 第1に、声が人格を身体化する最初のチャネルであること
- 第2に、汎用TTSでは人格の温度が最後の出口で失われること
- 第3に、Mumon のボイスは感情韻律とリアルタイム性に特化していること
- 第4に、二段階生成が遅延隠蔽を可能にし、共在感を生むことです
そのうえで、人格がユーザーにとって知覚されるチャネルは、もちろん声だけではありません。
もう1つの大きなチャネルが、視覚です。
次節では、同じ原理が視覚チャネルにもどう拡張されるのか、そしてアバターが人格の視覚化をどのように担うのかを論じます。本節で置いた Latency over Fidelity の原則も、二段階生成による遅延隠蔽の考え方も、次節のアバター設計にそのまま貫かれていきます。
つまり本節は、表現レイヤーの入口であり、次節の視覚表現を受け止めるための聴覚的な基礎でもあります。