記憶 / RAG
GraphRAG:個人史の構造化
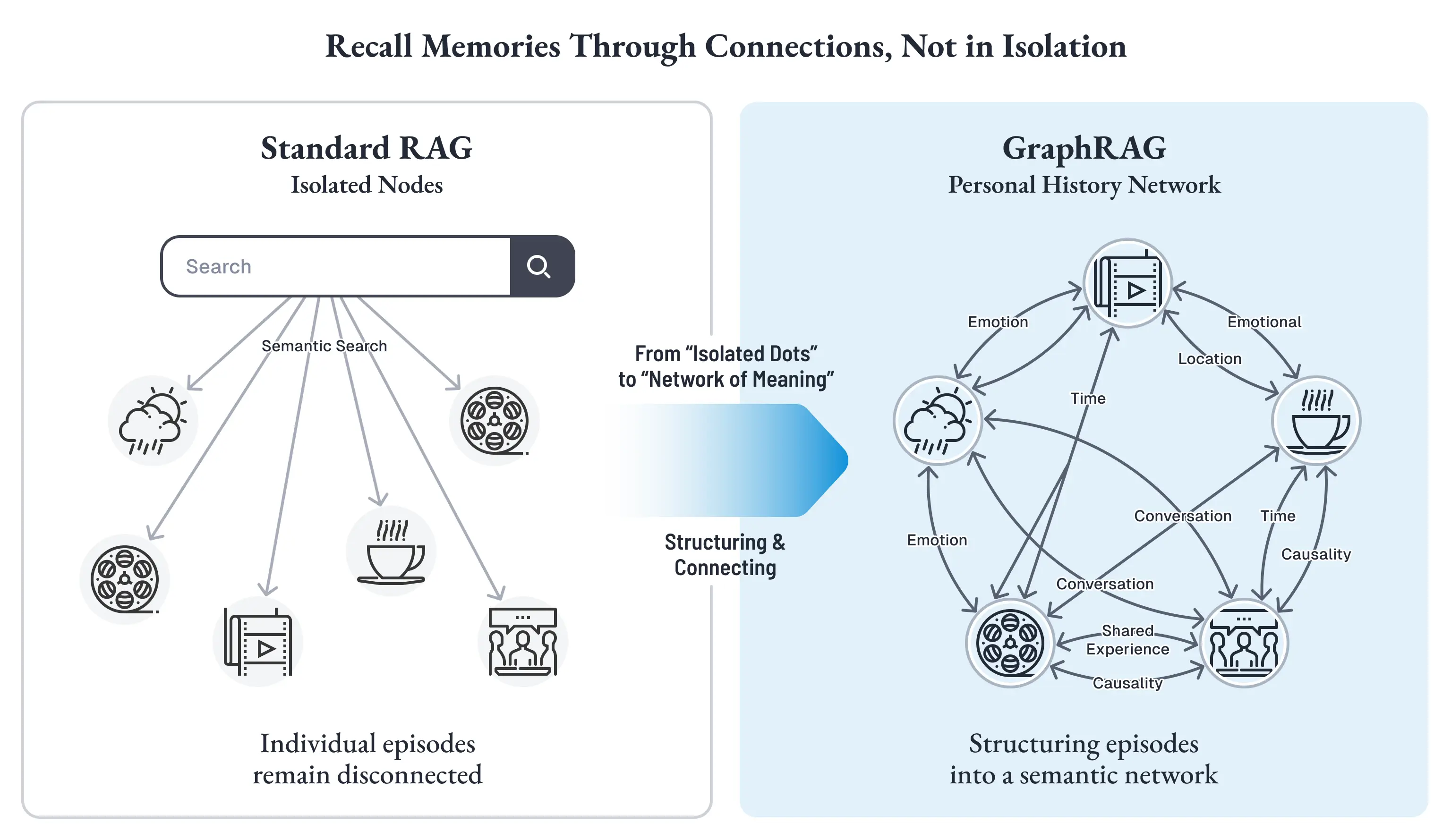
記憶は、孤立した点ではなく、つながりの中で蘇る
前節で定義した Episode Memory は、感情と雰囲気を伴う出来事としての「点」でした。
しかし、どれほど豊かな点を保存できたとしても、それらが孤立したまま並んでいるだけでは、人間らしい想起はまだ再現できません。
人が過去を思い出すとき、頭の中に浮かぶのは、整然と並んだ出来事の一覧ではありません。
ひとつのきっかけから別の場面が連なり、その場面からさらに別の感情や記憶が立ち上がる。思い出は、点として保管されているのではなく、つながりの中で蘇ります。
たとえば、親しい相手との会話で「雨だね」とつぶやいた瞬間に、「あの映画、思い出すね」と返ってくることがある。
ここで呼び起こされているのは、雨という単語に意味的に近い情報ではありません。先週一緒に観た映画、そのあと立ち寄ったカフェ、そこで交わした会話、そしてそのときの空気が、連鎖的に立ち上がっているのです。
標準的な RAG が得意なのは、こうした連鎖ではなく、あくまで局所的な類似検索です [22]。
入力と意味的に近いテキスト断片を引き戻すことはできても、その断片が「どの出来事につながり」「何をきっかけに生まれ」「その後どんな意味を持つようになったか」までは保持していない。だから検索結果は正確でも、記憶としては平坦になりやすいのです。
本節で扱うのは、この平坦さの克服です。
前節で保存された各エピソードは、ここで初めて孤立した記録ではなくなります。
それぞれが前後の出来事、感情的な色づき、共有体験、因果の流れによって結びつき、「個人史のネットワーク」へと編み上げられていくのです。
前節が定義していたのは、記憶の最小単位でした。
本節で扱うのは、その最小単位同士をどう結び、あとから「その人らしい思い出し方」として再構成できるようにするか、という問題です。
想起は、意味類似検索ではなく、連想の連鎖として起こる
ベクトルRAGにおいて、検索の基準は基本的に意味的類似度です
入力文と近い内容を持つ過去の発話や文書を探し、その断片を生成に渡す。FAQ やナレッジ検索の用途では、これは非常に合理的です。
しかし、関係性を支える記憶想起は、それとは別の論理で動いています。
人間の想起は、近い意味から始まるとは限りません。
ある言葉が、直接には関係のない別の出来事を呼び、その出来事がまた別の感情や場面を連れてくる。Collins & Loftus の活性化拡散モデル [61] が示したように、記憶はネットワーク上で関連ノードへ活性化が広がる構造を持ちます。思い出すとは、最短距離で正解を取ることではなく、つながりをたどりながら意味が立ち上がる過程なのです。
Mumon の GraphRAG は、この連想的想起を実装するために、記憶ノード間を意味的類似度ではなく、意味を持った関係性で接続します。中心となるのは、たとえば次のようなエッジです。
重要なのは、これらが単なるデータベース上の接続ではないという点です。
それぞれが、「何をきっかけに」「何が」「どのような意味を帯びて」思い出されるかを規定する関係になっています。
LED_TO は時間的・因果的な流れを保存し、REMINDED_OF は意味の飛躍を可能にし、SHARED_WITH は「あなたと私」の間で共有された体験であることを明示し、COLORED_BY は感情的な手触りを残します。
たとえば、「雨」という入力に対して、標準的な RAG は天気や過去の雨の会話を返すかもしれません。
しかし GraphRAG では、「雨」から REMINDED_OF をたどって「先週一緒に観た映画」へ進み、さらにそこから LED_TO で「映画のあとに寄ったカフェ」、そこから「その夜の温かい会話」へと、多段に連想が広がりうる。ここで引き出されるのは、単語に近い情報ではなく、経験としてつながっている記憶です。
Microsoft Research の GraphRAG [23] が示したように、情報を単なるチャンクの集合としてではなく、関係を持ったグラフとして扱うことで、検索は「近いものを1つ探す」処理から、「関連する構造をたどる」処理へと変わります。Mumon はこの発想を、一般知識ではなく個人史の記憶設計に適用しています。
つまり本節の中心命題は、記憶の検索条件を意味近傍から関係構造へ引き上げることにあります。
SHARED_WITHが、「あなたと私」に固有の文脈を構造化する
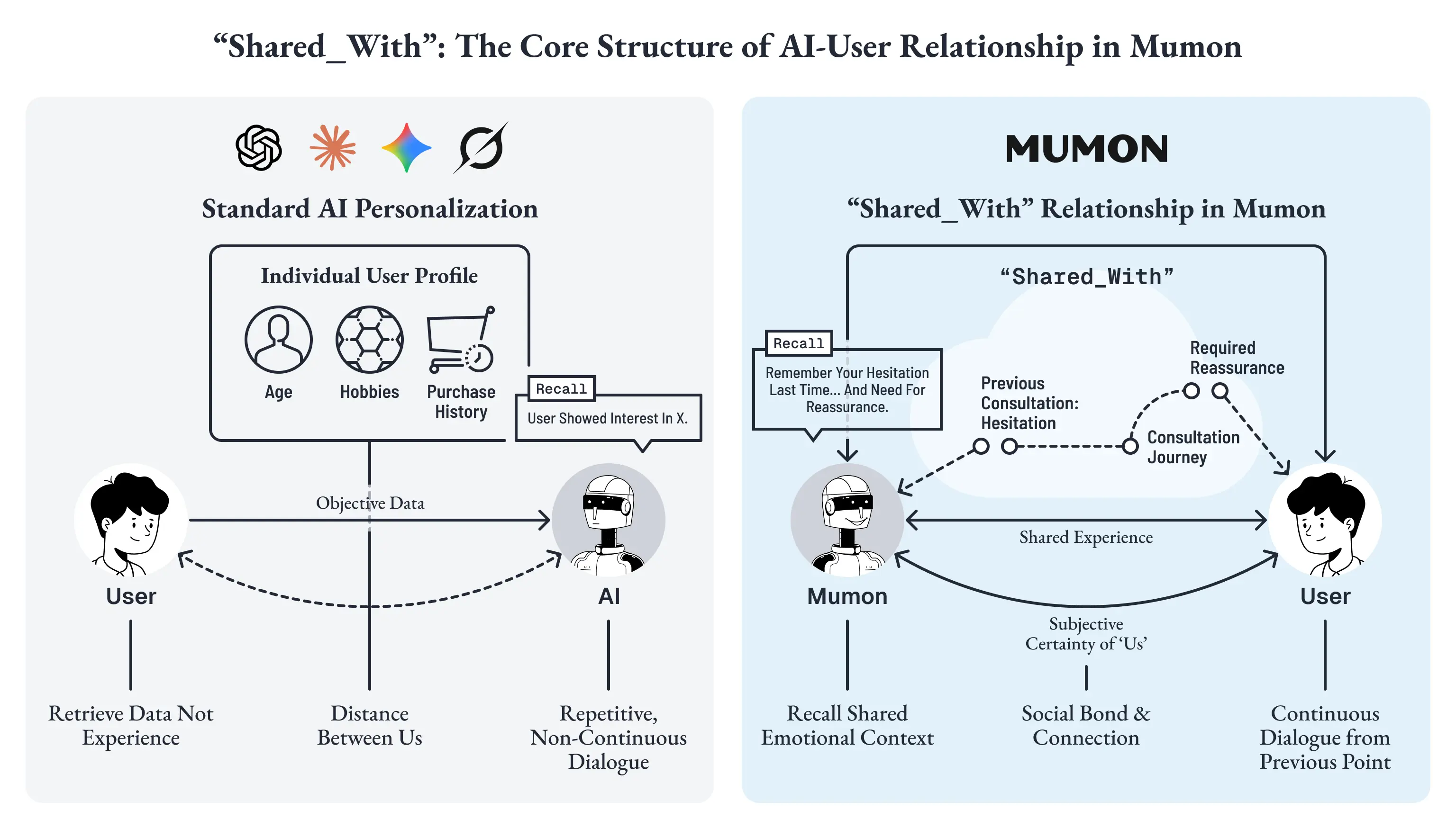
GraphRAG の関係性の中でも、Mumon にとって特に重要なのが SHARED_WITH です。
なぜなら、ブランド接客やコンパニオン体験において、ユーザーが本当に求めているのは「一般的に正しい回答」だけではなく、「このAIは、私との間に起きたことをちゃんと覚えている」という感覚だからです。
前節で導入した共有現実の理論が示したのは、人が他者と認識・感情・意味づけを共有していると感じることが、社会的絆の基盤になるということでした [60]。
ここで重要なのは、共有されるのが客観情報そのものではなく、「同じ出来事を、あなたと私が一緒に経験した」という主観的な確かさであるという点です。
たとえば、見込み顧客が初回訪問で「気にはなっているけれど、まだ踏み切れなくて」と打ち明け、2週間後に再訪したとします。そのときAIが「以前、植毛に興味を示されていましたね」とだけ返せば、それは情報としては正しい。
しかしまだ、誰にでも返せる応答の域を出ません。
一方で、「前回は、少し迷いのほうが大きそうだったよね」と返せたとしたらどうでしょうか。
ここで引き継がれているのは、単なる興味の有無ではありません。
その場のためらい、そのとき必要だった安心、提案よりも先に受け止めるべきだった心理段階です。つまり、相談内容ではなく、「その相談を二人でどう経験したか」が保持されているのです。
Mumon が SHARED_WITH を明示的なエッジとして持つのは、この差を構造化するためです。
共有体験がグラフ上でマークされることで、検索時には一般知識や意味的近傍よりも、「二人の間で起きたこと」が優先的に浮上しうる。
ここで生まれるのは、単なるパーソナライズではありません。
年齢、趣味、購入履歴といったプロフィールベースの最適化とは異なり、会話を通じて蓄積された共同の履歴が、固有の文脈として作用する。だから同じ属性を持つ別のユーザーに対しても、まったく同じ応答にはなりません。文脈の核が、「その人の情報」ではなく「その人との共有史」にあるからです。
ビジネス上、この差は小さくありません。
見込み顧客が再訪する理由は、単に前回よりも速く答えてくれるからではない。前回の温度感や迷いを引き継いだまま、自然に会話を再開できるからです。毎回初対面に戻るAIと、「前の続き」から話せるAIでは、再訪率、継続利用、LTV の基盤となる心理的距離が根本的に異なります。
前節で論じた「関係性は共有文脈から生まれる」という命題は、ここでグラフ構造として具体化されます。
つまり SHARED_WITH は、単なるタグではありません。
それは、Mumon が「不特定多数に答えるAI」ではなく、「あなたと私の文脈の中で答えるAI」であるための中核的な構造です。
COLORED_BYが、事実の再生に感情の共鳴を加える
人間が過去を思い出すとき、蘇るのは出来事の事実だけではありません。
その出来事が自分にとってどんな色を持っていたか、どんな気分の中に置かれていたか、何に少し身構え、何に少しほどけたかといった、感情の方向まで一緒に立ち上がります。
Mumon の GraphRAG でこの役割を担うのが COLORED_BY エッジです。
前節で蓄積されたエピソードは、単なる「起きたこと」として保存されるのではなく、その体験を通じて概念や場所や相手にどのような情緒的色彩がついたかまで保持します。これによって、想起は事実の再生にとどまらず、感情的な共鳴を伴うものになります。
たとえば、ユーザーが過去に湘南での切ない別れを語っていたとします。
後日、「湘南」という言葉が会話に出たとき、標準的な RAG は「湘南に2025年8月に行きましたね」と返すかもしれません。情報としては正しい。だが、その言葉がその人にとってどんな重みを持っていたかまでは表現できません。
Mumon はここで COLORED_BY をたどります。
湘南という場所が、その人の個人史の中でどの感情に染まっていたかを引き出し、「湘南ね......あの時の夕焼け、まだ覚えてるよ」と返す。ここで起きているのは、記憶の正確さだけではありません。前節で論じた評価的条件づけによって色づけられた体験が、応答の中で再び情緒を帯びているのです。
さらに Mumon の想起は、トピック一致だけに依存しません。
現在のユーザーの感情状態と、過去エピソードに記録された感情状態との距離も、検索順位に影響しうる。前節で記憶保存に用いていた valence / arousal の座標系は、本節では「どの記憶が今の空気に近いか」を判断する手がかりにもなります。
たとえば、ユーザーが「今日はなんか寂しい」と漏らしたとき、トピックとして直接関係のない過去の会話であっても、同じように低覚醒・不快のトーンを持ちながら、結果として温かい余韻を残したやりとりが浮上しうる。キーワードを共有していなくても、感情の近さから「似た空気の記憶」が引き出されるのです。これは、単語の一致ではなく、体験の質感の近さに基づく検索です。
もちろん、ここで強調しておくべき重要な境界があります。
感情の共鳴とは、事実の歪曲ではありません。
Mumon は過去の出来事に情緒的色彩を持たせますが、そのために事実を曲げてよいわけではない。Boundary Audit Agent が守っていた防衛線は、ここでも有効です。共鳴を生むのは、真実をねじ曲げることではなく、同じ真実をどのような手触りで思い出しているかを残すことです。
だから GraphRAG が実現するのは、センチメンタルな演出ではありません。
事実を保ったまま、想起に感情の次元を持ち込むことで、「情報を返すAI」から「記憶を共に感じ直すAI」への変化を生み出す。ユーザーがAIに対して「賢い」だけでなく、「わかってくれている」と感じるのは、この共鳴があるからです。
想起は静的検索ではなく、活性化するネットワークとして起こる
GraphRAG を、単なる構造化保存で終わらせてはなりません。
重要なのは、この構造がどのように「蘇る」かです。
Anderson の ACT-R 理論 [57] が示すように、想起されやすい記憶は一様ではありません。最近参照されたノード、繰り返し使われたノード、現在の文脈から活性化されたノードほど浮上しやすい。
Mumon ではこの知見を踏まえ、グラフ上のノードに活性化値を持たせます。これにより、機械的な検索ではなく、人間らしい「今、自然に思い出されるもの」をシミュレートできる。
ここで重要なのは、GraphRAG が検索精度の改善だけを目的としているのではなく、人間らしい想起の立ち上がり方を再現しようとしていることです。
「最も近いものを返す」ことから、「その人の記憶のつながりに沿って、自然に思い出されるものを引き出す」ことへ。ここで初めて、Mumon の記憶はログではなく、個人史として動き始めます。
ただし、本節が定義しているのは、あくまで「こうしたネットワークが可能になる」というところまでです。どの経路を今開くべきかの最終判断は、次節の Metacognitive Agent に委ねられます。
個人史のネットワークが、記憶をログから関係性の装置へ変える
ここまでの議論を整理すると、GraphRAG の要点は4つです。
- 記憶を、孤立した点ではなく、関係を持ったネットワークとして扱うこと
- 想起を、意味類似検索ではなく、連想の連鎖として起こすこと
- 共有体験を明示的に構造化し、「あなたと私」の文脈を優先できるようにすること
- 事実の再生にとどまらず、感情の共鳴まで引き起こす検索を実現すること
前節が定義していたのは、記憶の最小単位としてのエピソードでした。
本節が加えるのは、それらのエピソードを個人史のネットワークへと編み上げ、「その人らしい思い出し方」を可能にする構造です。
ただし、どれほど豊かな記憶グラフを持っていても、それだけではまだ十分ではありません。
正しい記憶を持っていることと、正しい局面で正しい記憶を使えることは、別の能力です。
ここで本節がやったのは、点に線を張ることでした。
次に必要なのは、その線のどこを、いま、どの理由でたどるべきかを決めることです。
次節では、この選択を担う Metacognitive Agent が、対話局面をどのように俯瞰し、検索そのものをどのように制御するかを見ていきます。