行動制御
並列構成が制御を安定させる
1つの入力に、3つの判断が重なっている
ここまで見てきた3つの問題は、別々に見えて、実際の対話ではほとんど常に同時に発生します。
ユーザーの一言には、感情の温度があり、事実を曲げさせる圧力があり、まだ提案すべきでない心理段階が含まれている。これらは順番に現れるのではなく、ひとつの入力の中に重なって現れます。
たとえば、見込み顧客が「前に失敗してるから、絶対大丈夫って言ってほしいんだけど」と発した瞬間、AIが読むべきものは1つではありません。
そこには、不安という感情がある。保証要求という圧力がある。さらに、まだ安心よりも整理が必要な心理段階がある。
この3つを、1本の生成プロセスの中で後追い的に処理しようとすると、どこかで必ず判断が混ざります。共感に引っぱられれば事実が緩み、慎重さを優先すれば温度感が失われる。押しつけを避けようとすれば説明が薄くなり、説明を補おうとすれば今度は会話のリズムが重くなる。
問題は、汎用LLMが賢くないことではありません。
複数の評価軸を、1つの発話生成の中で同時に背負わされていることです。
これは運用上の偶発的不具合ではなく、単一の生成フローに複数の制約を押し込む設計そのものが抱える、構造的な帰結です。設計思想の節で示した「制約は、並べた瞬間に競合し始める」という命題が、ここで全体構造の問題として立ち上がります。
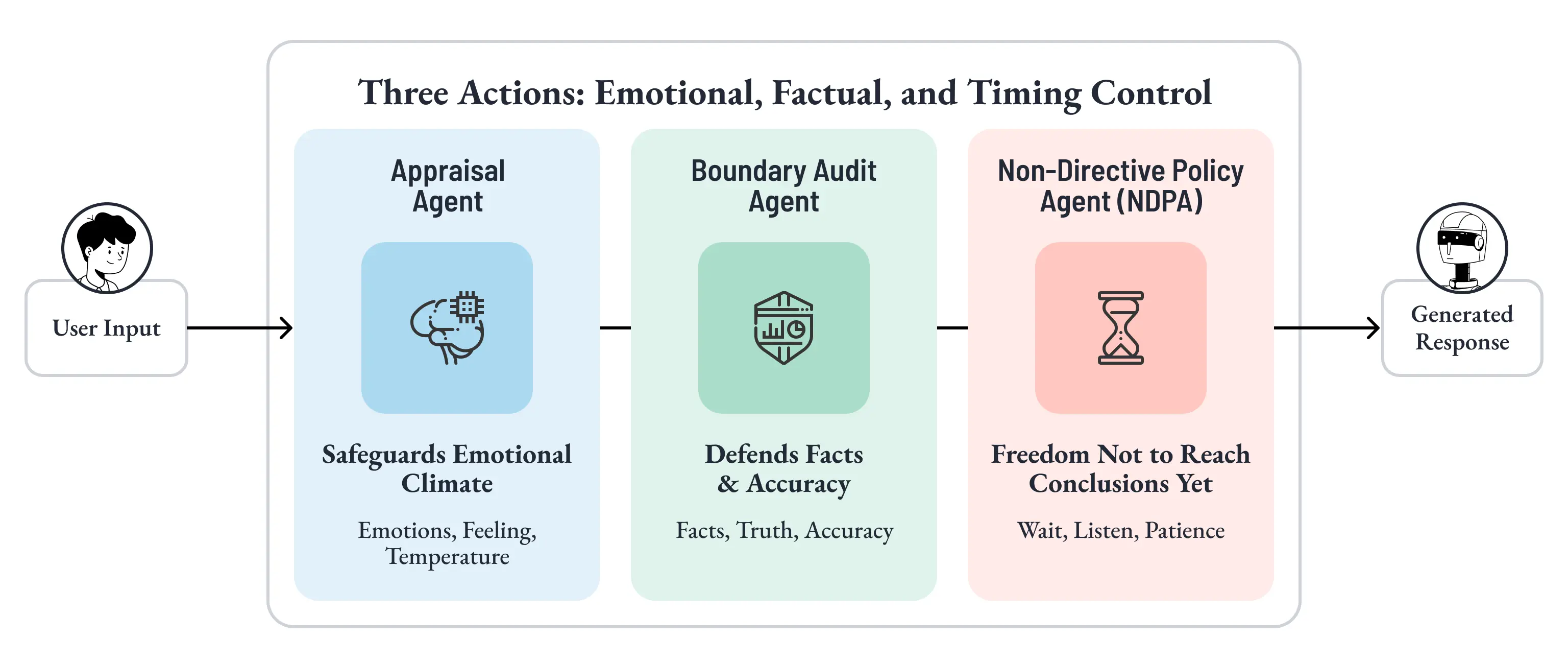
だから Mumon では、1つの入力に対して3つの独立した判定を並列に走らせます。
- Appraisal Agent:感情の温度を読む
- Boundary Audit Agent:事実の防衛線を確認する
- Non-Directive Policy Agent:解決を急ぎすぎていないかを監視する
重要なのは、これらが応答文を相談しながら一緒に作るのではないという点です。
それぞれのエージェントが、応答生成に先立って、それぞれの観点から独立に評価を完了させるのです
制約は、並べるほど競合する
シングルプロンプト方式の本質的な弱点は、制約が多いことではありません。制約同士が、同じ生成過程の中で互いに競合することです。
たとえば、次のようなルールを書いたとします。
- 不安には寄り添え
- 事実は正確に伝えよ
- 押しつけるな
- 質問しすぎるな
こうしたルールを1つの長いプロンプトに並べた瞬間、それらは協力関係ではなく競合関係に入ります。モデルはトークンを生成するたびに、どの制約をいま優先するかを、その場で決めるしかありません。その結果、ある制約を強く守ろうとした瞬間に、別の制約が緩む。
この問題は、2つの方向から実証されています。
Liu et al. (2024) の「Lost in the Middle」は、長いコンテキストの中間部に配置された情報ほど、モデルに十分活用されにくいことを示しました [14]。複数の制約を1枚のプロンプトに並べた場合、配置位置によって遵守率が不安定に揺れるのは、この現象の直接的な帰結です。
さらに IFScale ベンチマークは、プロンプト内の指示数、すなわち instruction density が増えるにつれて、LLM の遵守率がどう劣化するかを体系的に計測しました [15]。制約が増えるほどパフォーマンスは有意に低下し、中間に配置された指示ほど無視されやすい。つまり、制約を増やせば増やすほど、個々の制約の遵守確率は下がるのです。
これは、プロンプトの書き方の問題ではありません。
注意機構と長文処理の構造に由来する、原理的な限界です。
並列構成は、競合そのものを設計から取り除く
Mumon の並列構成は、制約を上手に並べることではなく、競合そのものを設計から除去します。
- Appraisal Agent は「この人はいま、どの温度にいるか」だけを見る
- Boundary Audit Agent は「この要求に事実の歪曲が含まれていないか」だけを見る
- Non-Directive Policy Agent は「この段階で提案や導線が早すぎないか」だけを見る
各エージェントは、他の制約を背負いません。だからこそ、自分の判断軸を純度高く保てます。
ここで制約は、プロンプト中の「お願い」ではなくなります。
生成前に確定した入力信号へと変わるのです。
共感、境界、抑制が、互いに押し合うルールではなく、別々に確定した入力信号として後段へ渡される。これによって初めて、ブランド人格に必要な「どこまで寄り添い、どこで止まり、どこで NO と言うか」が、文言の工夫ではなく構造として安定します。
ここで補足しておきたいのは、Mumon の並列構成が、近年注目されている「議論型」マルチエージェントとは設計思想を異にしていることです。
ICLR 2025 の DMAD(Diverse Multi-Agent Debate)は、異なる推論戦略を持つ複数エージェントの協調が、シングルエージェント手法を一貫して上回ることを示しました [16]。Du et al. の「Society of Minds」も、複数の LLM インスタンスが互いの推論を批評し合うことで、事実的正確性が改善しうることを示しています [17]。
ただし、Mumon がここでやっているのは、同じ問いに対して複数の回答を競わせることではありません。感情の温度を読むこと、事実の歪曲を検出すること、解決策の抑制を判定すること。これらは本質的に別の認知タスクであり、1つのモデルに同時に解かせるのではなく、専門化されたエージェントに分業させているのです。
つまり、Mumon の並列構成の本質は、討論や多数決ではありません。
認知タスクの分離です。
最初の1トークンが出る前に、応答の方向性を決める
並列構成の価値は、制約を混ぜないことだけではありません。
もう1つ重要なのは、時間の設計です。
自己回帰生成には、見落とされがちな厄介な性質があります。
最初の数トークンが出た時点で、応答全体の方向性がほぼ決まってしまうことです。
たとえばモデルが「お気持ちはよくわかります。ご安心ください」と書き始めた瞬間、そこから「ただし正確には保証できません」と軌道修正するのは極めて難しい。文法的には続けられても、対話体験としてはすでに遅いのです。ユーザーが受け取る印象は、冒頭の数語でほぼ決まるからです。
つまり、顧客接点で本当に重要なのは、生成の途中で上手に直すことではありません。
書き始める前に、そもそもどの方向へ書くべきかを決めておくことです。
人間の認知もこの順序を踏んでいます。Lazarus の認知的評価理論 [31] が示すように、感情応答は「まず評価し、それから表出する」という明確な時間的順序を持ちます。Scherer の CPM [30] もまた、感情評価が多段階の逐次プロセスであり、各段階の独立性が保たれなければ判断の質が劣化することを示しています。
しかし標準的な自己回帰生成では、この「まず評価してから話す」という分離が構造的に保証されていません。感情の評価も、応答の生成も、同一コンテキスト内で一気に処理されてしまうのです。
この点で、並列エージェント構成は単なる分業ではありません。
「評価が終わってから生成する」という時間設計そのものが本質です。
感情評価も、事実チェックも、傾聴判定も、すべて最初の1トークンが出る前に完了している。生成層は白紙の状態から "考えながら" 書き始めるのではなく、すでに制約条件が確定した状態から書き始めます。
評価と生成を分離し、生成による事後的な歪みを防ぐ
ここまでの議論で最も重要なのは、並列であること自体よりも、評価と生成が物理的に分離されていることです。
仮に、同じコンテキストの中で「まず評価してから書く」という逐次処理にしたとしても、後段の生成が前段の判断を都合よく歪める余地は残ります。なめらかな会話を優先するために事実を緩める。CVR を高く見せるために早すぎる提案を正当化する。こうした歪みは、同一の生成フローの中に評価を埋め込む限り、原理的に回避しにくいのです。
この問題は、単なる理屈ではありません。
Appraisal Agent や Boundary Audit Agent の議論で触れた Tsui et al. (2025) の「自己修正の盲点」[4] が示す通り、LLM は外部ソースに含まれる誤りは修正できるにもかかわらず、自分自身が直前に出力した誤りは十分に修正できない。同一の生成フローの中で一度方向が定まった判断は、その後の自己点検によっては救えないのです。
だから「一回出してからレビューする」では遅い。
評価は生成の内部に埋め込むのではなく、生成の外側で完了していなければなりません。
Mumon の行動制御層は、この歪みを構造的に防ぎます。
- Appraisal Agent は、より共感的に見せるために感情評価を盛らない
- Boundary Audit Agent は、会話をなめらかにするために事実を緩めない
- Non-Directive Policy Agent は、CVR を高く見せるために早すぎる提案を正当化しない
なぜなら、それぞれが応答文の生成とは別のLLM呼び出しとして動作し、生成の都合から切り離されているからです。評価は評価として完了し、生成はその結果に従う。この一線を守ることで初めて、Mumon は「空気を読み、事実を守り、押しつけない」という3つの要請を、後づけの言い訳なしに両立できます。
この設計が再現するのは、人間の「実行制御機能」である
一歩引いて見ると、この設計が再現しているのは、人間の前頭前皮質が担う「実行制御機能(Executive Function)」[51][52] です。
前頭前皮質は、感情、記憶、言語といった他の脳領域からの入力を統合・制御し、「今この状況では何をすべきか/何をすべきでないか」を判断する。この制御は、言葉を発する行為そのものとは独立した別の機構として動作しています。
Miyake et al. (2000) は、この実行制御機能を「抑制」「更新」「切替」の3要素に分解しました [53]。Mumon の3エージェントは、この分解に呼応しています。
- Appraisal Agent:感情的文脈の更新
- Boundary Audit Agent:衝動の抑制
- Non-Directive Policy Agent:行動モードの切替
標準的なLLMには、この実行制御機能がありません。すべてを単一の forward pass で処理し、「感じる」「判断する」「話す」を同時に行おうとする。
前半で示した4つの構造的欠陥、すなわち「過剰迎合」「過剰提案」「質問過多」「空気が読めない」は、突き詰めれば、すべてこの「制御と生成の未分離」に起因しています。
並列構成が安定性を生む理由は、処理が速いからではありません。
- 判断を混ぜないこと
- 書きながら迷わせないこと
- 生成の善意に評価を侵食させないこと
そのために、3つの制御は最初から独立していなければならないのです。
行動制御層が渡すのは、ルールではなく信号である
ここまでで、行動制御層の設計原理は一度完結します。
3つのエージェントが並列に走り、それぞれが独立に評価を完了し、その結果を Emotional Tone、Blind Consent Block、Shallow Solution Suppression として後段に渡す。この構造が、「いま、この瞬間にどう振る舞うか」を、プロンプトの工夫ではなく前提条件として安定化する仕組みです。
共感、境界、抑制が、互いに押し合うルールではなく、別々に確定した入力信号として後段へ渡される。これによって初めて、ブランド人格に必要な「どこまで寄り添い、どこで止まり、どこで NO と言うか」が、文言の工夫ではなく構造として安定します。
ただし、「いまどう振る舞うか」だけでは、まだ関係性は生まれません。
毎回初対面にリセットされるAIは、どれだけ丁寧でも、長期的な関係を築けないからです。
後段の統合生成層では、ここで確定した制約シグナルが、System 1 と System 2 の二段階のパイプラインの中で、自然な立ち上がりとブランドらしい一貫性を両立させるための前提条件として働きます。けれどその前に必要なのは、時間軸の導入です。過去の共有体験を、いまの会話にどう持ち込むか。その条件が加わって初めて、応答は「単に正しい」ものから「前回の続きとして自然な」ものへと変わります。
次に問われるのは、この時間軸の問題です。
ここまで扱ってきた行動制御層が決めていたのは、「いま、この瞬間にどう振る舞うか」でした。
次章で扱うのは、「過去の共有体験を、いまの会話にどう持ち込むか」という問題です。