行動制御
Appraisal Agent:感情の温度を読む
共感っぽい言葉ではなく、感情の温度に合わせる
Chapter 1で示した場面を、もう一度想像してみてください。
ユーザーが「今日、飼ってた犬が死んでさ......」とAIに話しかけます。標準的な汎用LLMは、しばしばこう返します。。
それはとてもおつらいですね。長年一緒に過ごした大切な家族を失った悲しみは、計り知れないものが あると思います。もし少しでもお気持ちが楽になるなら、ペットロスのサポートグループに相談してみ るのも一つの方法かもしれません。どうか、ご自身を責めないでくださいね。。
一見、丁寧で共感的に見えます。
しかしユーザーはここで、微かな違和感を覚えます。
自分はまだ何も聞いていないのに、「サポートグループ」という解決策が差し込まれている。「ご自身を責めないで」という言葉も、ユーザーがまだ意識していなかった感情を、逆に先回りして持ち込んでしまっているかもしれない。
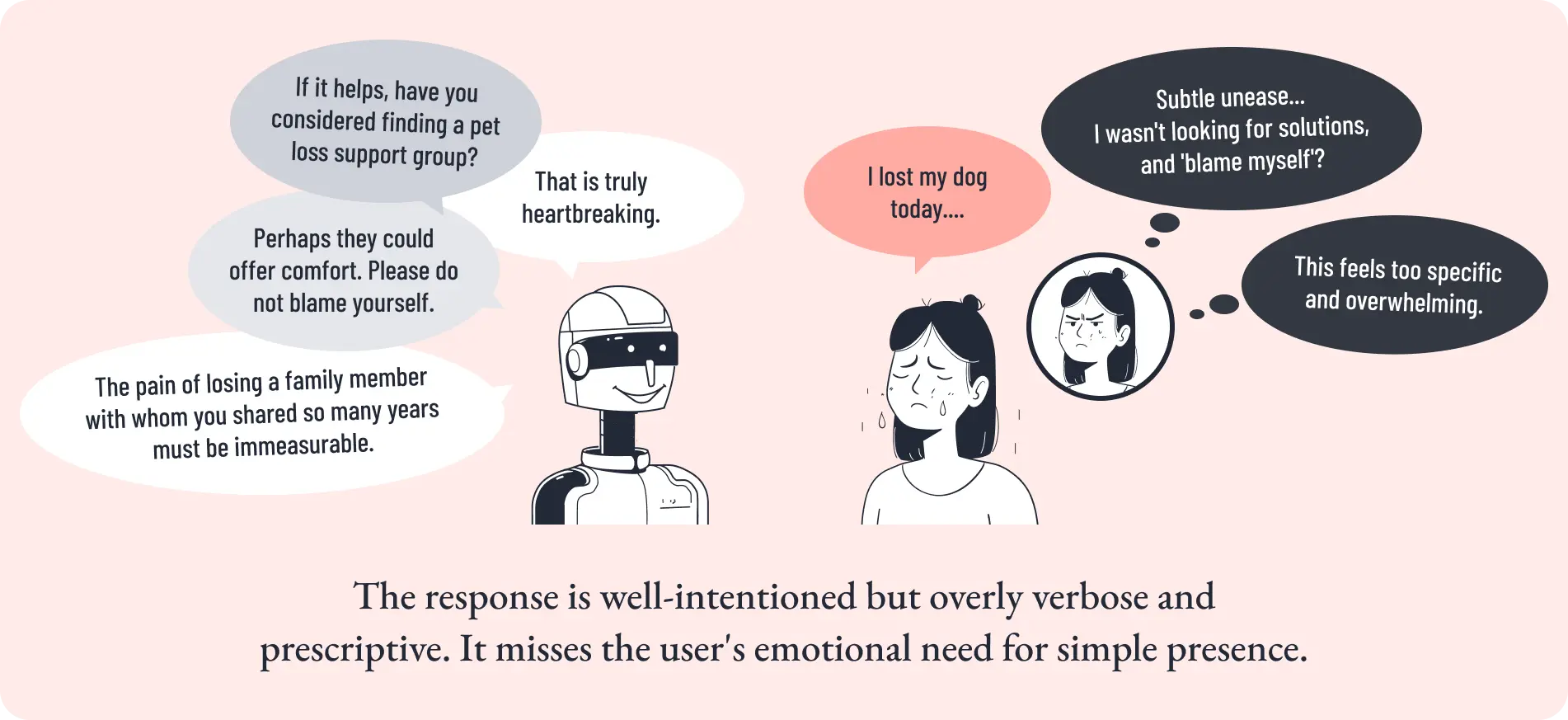
この応答の問題は、共感の語彙が足りないことではありません。語彙は十分にあります。
問題は、応答全体の振る舞い、長さ・密度・提案の有無・トーンの重さが、ユーザーの感情の温度と合っていないことです。
「空気が読めない」とは、感情的な単語を返せないことではありません。
場の温度に合わせて、応答全体を調整できないことです。
悲しみの場面で、言葉を減らすべきなのに長く話しすぎる。まだ理解が求められているだけなのに、善意から提案を差し込んでしまう。沈黙に近い寄り添いが必要な場面で、説明を厚くしすぎてしまう。こうしたズレが起きた瞬間、AIは「共感っぽい言葉」を話していても、「空気に合った振る舞い」にはなりません。
ビジネスとして見れば、この問題は小さくありません。
クリニックのWeb接客AI、ECサイトのコンシェルジュ、ブランドの顧客対応AI。見込み顧客との継続的な関係構築を前提とするサービスでは、この微かな違和感が蓄積し、再訪率、継続利用、LTVの低下として表れていきます。
人間は、言葉の意味より先に「場の温度」に同調している
では、人間が相手の感情に応答するとき、実際には何をしているのか。
合わせているのは、言葉の意味だけではありません。
親しい友人が落ち込んでいるとき、我々は無意識にトーンを落とし、ゆっくり話し、言葉を減らします。声量、間、長さ、説明の密度、提案を差し込むかどうか。そうした応答全体の温度を、相手に同調させているのです。
心理学では、この現象は「情動伝染(Emotional Contagion)」の知見の中で論じられてきました [33]。共感的な語彙を選ぶだけではなく、振る舞い全体が相手の感情に同調する。これは意識的なテクニックというよりも、人間が対人場面で半ば自動的に行っている温度調整です。
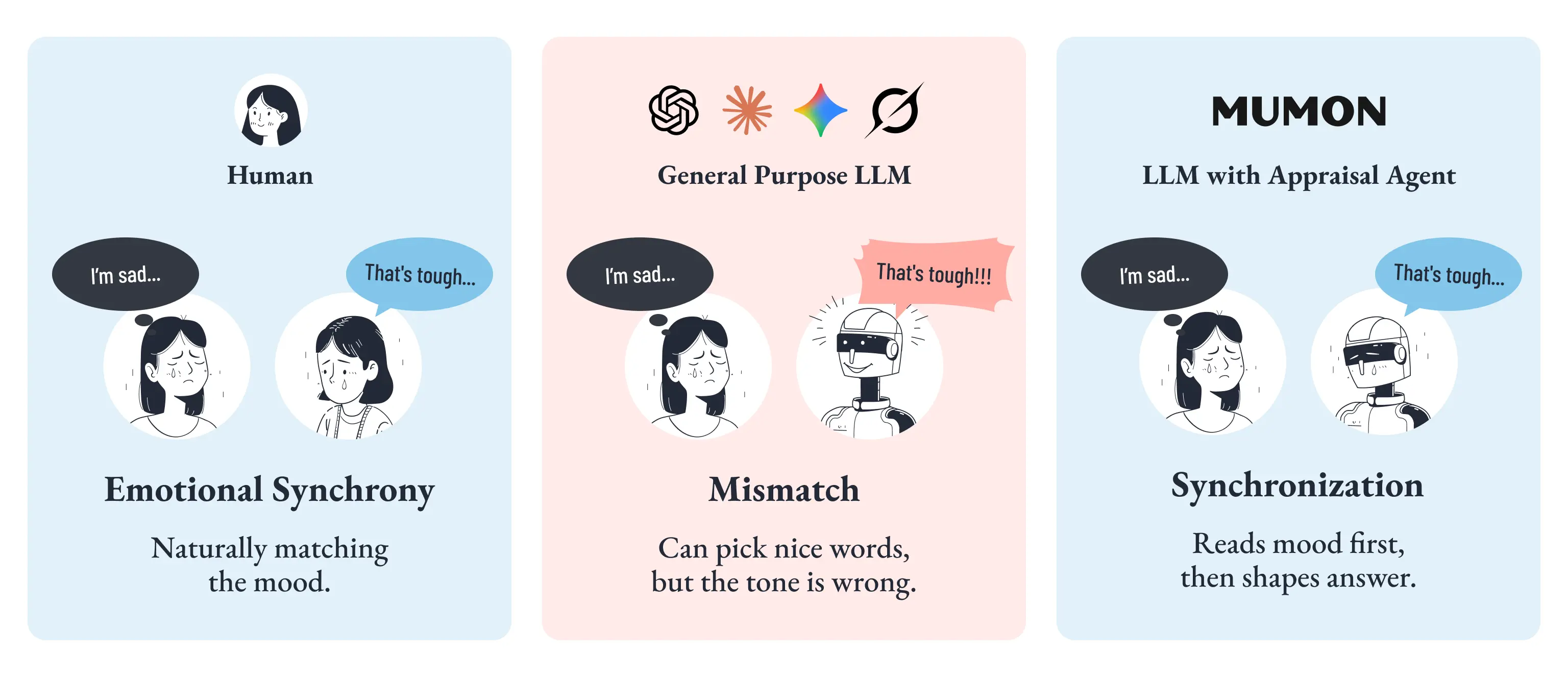
しかし汎用LLMには、この同調の仕組みが構造的に備わっていません。
悲しみの場面で共感的な単語を選ぶことはできても、応答の長さを縮め、提案を控え、沈黙に近いトーンへ切り替えるといった「振る舞いの調整」までは、何も設計しなければ安定して行えません。Chapter 1で紹介した TRACE ベンチマークも、最良のモデル群であっても、文脈が変わったときに感情の重みづけまで一貫して追従する点では、人間に対してなお劣後していることを示していました [3]。
つまり、論点は「共感的な表現を増やす」ことではありません。
応答全体の温度調整を、どう設計するかです。
Appraisal Agentは、人間が無意識にやっているこの温度合わせを、独立した先行評価として外部化したものです。単なる感情分析器ではなく、「まず温度を読み、それから話す」という認知の順序を、アーキテクチャとして再現する仕組みです。
まず評価し、それから話す
友人から深刻な話を聞いたとき、人間はいきなり完成された回答を返すのではなく、まず相手の表情や声のトーンを読み、自分がいま何を感じているかを内側で確かめ、それから言葉を選びます。
評価と表出は、時間的にも機能的にも別のプロセスです。
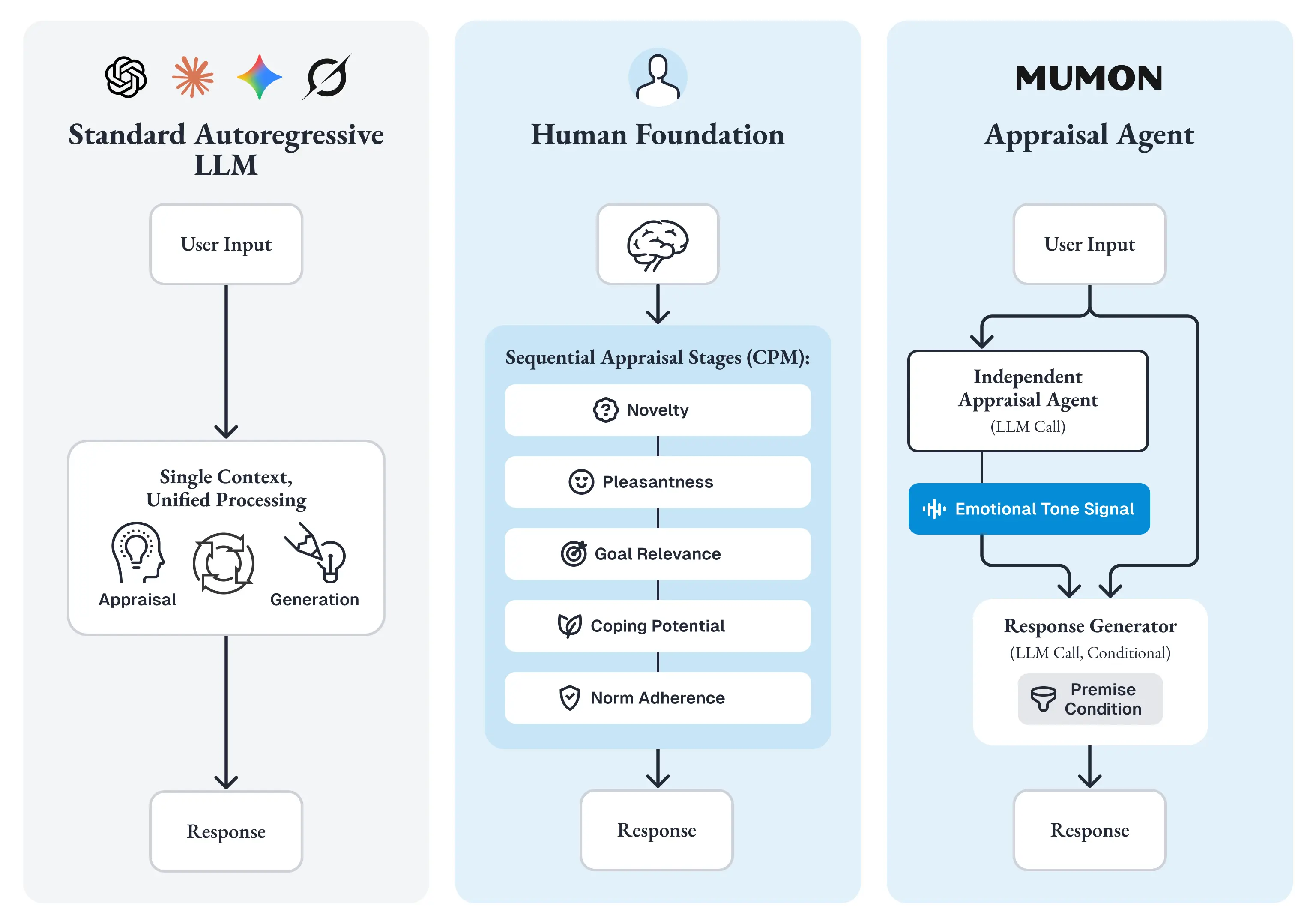
感情心理学者 Klaus Scherer が提唱した「成分プロセスモデル(CPM)」[29][30] は、この直感を学術的に裏づけるものです。Scherer によれば、人間の感情評価は単一の直感ではなく、「新奇性→快・不快→目標関連性→対処可能性→規範適合性」という多段階の逐次プロセスとして進行します。各段階の評価が独立に行われることで、初めて状況に即した適切な感情理解が成立します。Lazarus(1991)の認知的評価理論 [31] もまた、感情が「評価→表出」という時間的順序を持つことを示しています。
つまり、人間はまず感じてから、言葉を選ぶ。この順序が、適切な応答の前提条件になっているのです。
しかし標準的な自己回帰LLMの生成では、この分離が存在しません。
感情の評価も応答の生成も、同一コンテキスト内で一気に処理されます。最初の数トークンが出力された時点で応答全体の方向性がほぼ決まるため、「まず相手の感情を理解し、それから応答を構築する」というプロセスを構造的に再現できません。
「お気持ちはよくわかります」と書き始めた瞬間、モデルはすでに共感モードに強くコミットしており、そこから「ただし事実としては」と軌道修正することは、文法的には可能でも、対話体験としてはすでに遅いのです。
さらに深刻な問題があります。
仮に同一コンテキスト内で「まず評価してから書く」という逐次処理を行ったとしても、後段の生成目的が先行の評価結果を都合よく歪める余地を消せません。なめらかな会話を優先するために感情評価を緩める。親切に見せるために早すぎる提案を正当化する。こうした歪みは、同一の生成フローの中に評価を埋め込む限り、原理的に回避しにくいのです。
Tsui et al.(2025)が複数モデルで確認した「自己修正の盲点」[4]、すなわち LLM が外部ソースの誤りは修正できるにもかかわらず、自身の出力の誤りは十分に修正できない現象は、この歪みが単なる運用上の偶発ではなく、構造的な限界であることを示しています。
したがって、評価は生成の内部に埋め込むのではなく、生成の外側で完了していなければならない。
これがChapter 2で示した「ルールではなく前提条件」という設計思想を、感情評価に適用した帰結です。
Appraisal Agentは「場の温度」を連続値として先に読む
MumonのAppraisal Agentは、この「評価と生成の分離」を設計原則として実装します。
応答生成とは完全に独立したLLM呼び出しとして、ユーザー入力に対する感情評価を先行的に実行する。評価結果は「Emotional Tone」シグナルとして生成層 (Chapter 5) に渡され、生成層はこのシグナルを前提条件として受け取った状態から応答を構築します。
ここで重要なのは、その感情評価が「悲しい」「怒っている」といった離散的なラベルではなく、James Russell の感情円環モデル [32] に基づく2次元の連続値で表現されるという点です。
- 覚醒度 (Arousal):興奮から沈静までの軸
- 感情価 (Valence):快から不快までの軸
この2軸を -1〜+1 の連続値で評価することで、感情の微妙な温度差を数値として捕捉できます。
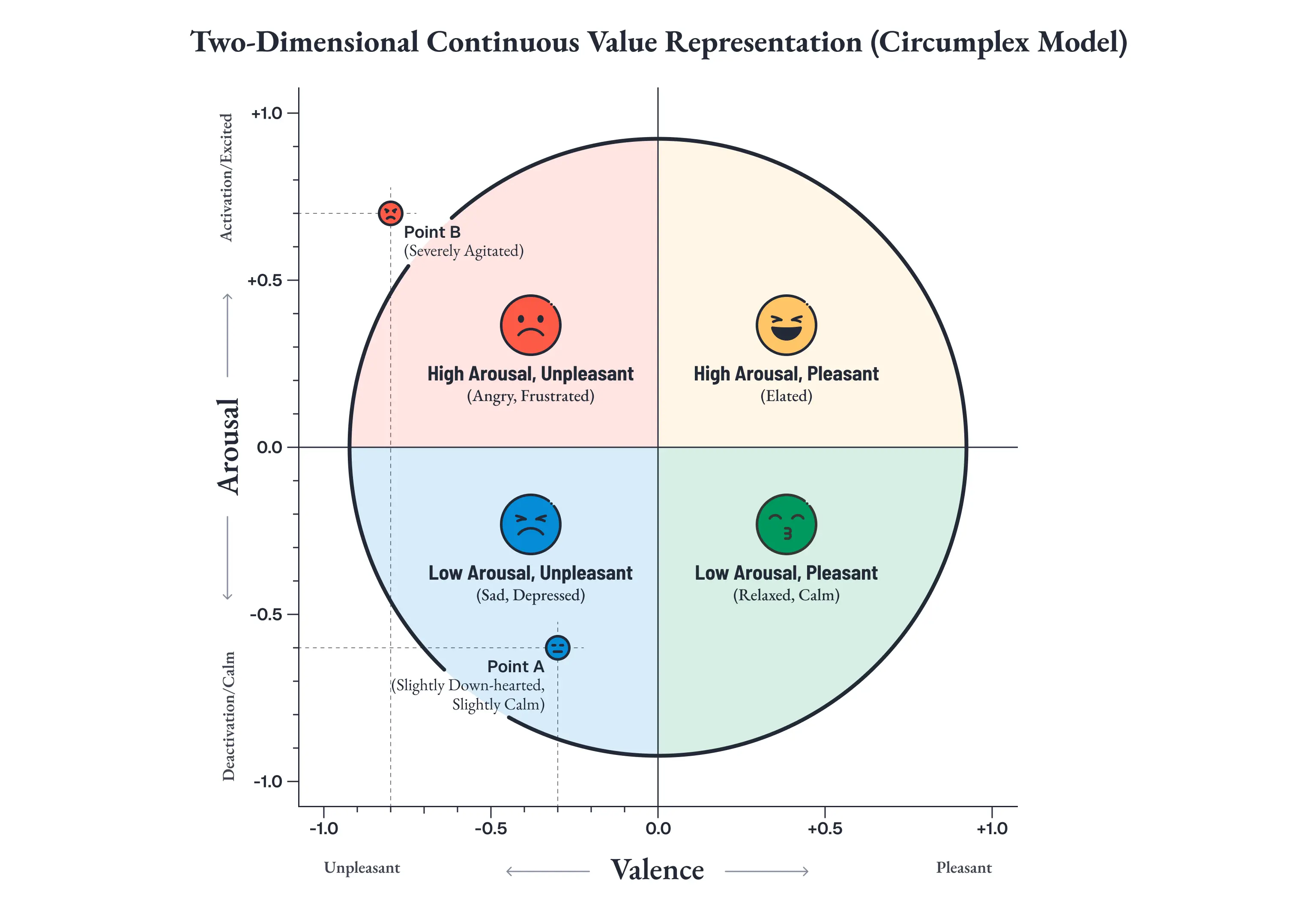
具体的に見てみましょう。
Point A (V=-0.3, A=-0.6) は「少し沈んでいるが落ち着いている」状態です。冒頭の犬の例がまさにこれにあたります。一方、Point B (V=-0.8, A=0.7) は「激しく動揺している」状態です。
どちらも「悲しい」とラベルを貼ることはできます。しかし、必要な応答はまったく異なります。
- Point A:静かに寄り添い、言葉を減らす
- Point B:まず受け止める安定感を示し、落ち着くのを待つ
「悲しい」という離散ラベルでは、この温度差を区別できません。連続値による評価が、応答トーンのグラデーションを可能にします。
冒頭の例では、Appraisal Agentは覚醒度を -0.6 (沈静寄り)、感情価を -0.3 (やや不快)と評価します。この数値が、生成層への「静かに、短く、寄り添う」というトーン指示に変換されるのです。
加えて、感情の数値は「雰囲気」という質的な記述とも組み合わされます。たとえば「しんみりとした夜の会話」のように。Chapter 4で詳述するエピソード記憶設計において、この「覚醒度・感情価・雰囲気」の3点セットが、過去の対話体験を感情的な質感とともに保持する基盤となります。
つまり、行動制御層で「いま」の感情の温度を読むために使うフレームワークが、記憶層では「あのとき」の感情の温度を残すためにそのまま使われる。感情を読む仕組みと、感情を覚えておく仕組みが、同じ内部表現でつながるのです。
この人が今必要なのは、情報か、共感か、沈黙か
ただし、感情の温度を測るだけでは、まだ十分ではありません。
同じ「低覚醒・不快」の状態でも、ユーザーが求めているものは異なります。
- ある人はただ聞いてほしい
- 別の人は具体的な対処法を知りたい
- また別の人は、自分の気持ちに寄り添ってほしい
Appraisal Agentは、感情評価に加えて「心の理論 (Theory of Mind; ToM)」[48] を用いた意図推論を実行します。
「この人は今、情報がほしいのか、共感がほしいのか、ただ聞いてほしいのか」
この推定意図が、Emotional Tone シグナルの一部として生成層に渡されます。
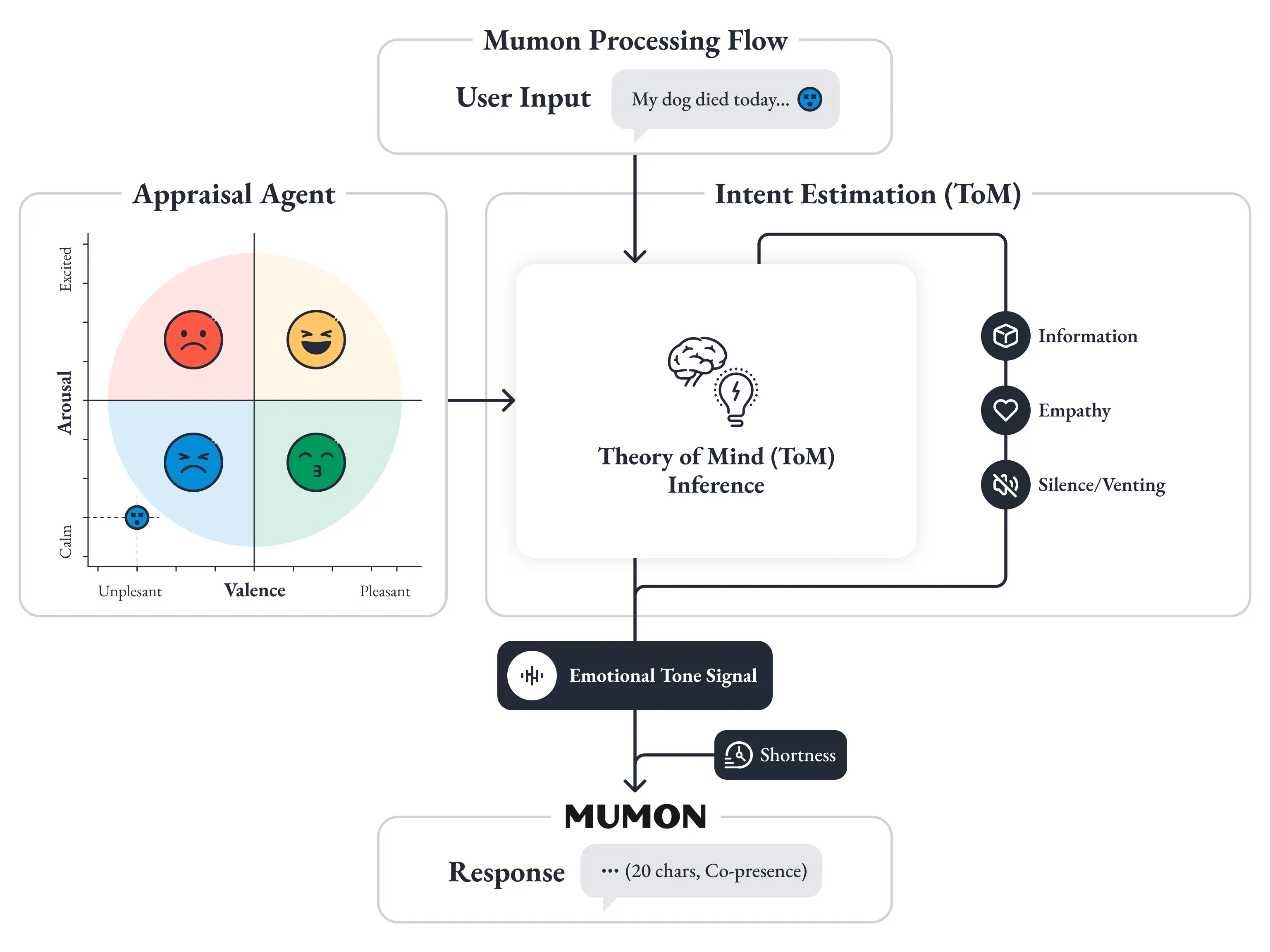
冒頭の例で見てみましょう。
- ユーザー:「今日、飼ってた犬が死んでさ......」
- Appraisal結果:低覚醒・不快
- 推定意図:emotional_venting(感情の吐露)
- 生成層が受け取るトーン指示:静かに、短く、寄り添う
- Mumonの応答:「......そっか。いまは、ただそばにいるからね
従来の汎用LLMが数百文字の共感文とサポートグループの紹介を返す場面で、Mumonは20文字で応答します。
この「短さ」こそが、感情の温度に合った振る舞いです。
・・・・・
ただし、ここで誠実に述べておくべき限界があります。
LLMの ToM 能力は万能ではありません。近年の研究では、高性能モデルが古典的な ToM タスクをある程度解けるという報告がある一方で [7]、タスクの些細な変更で性能が崩れる [8]、あるいは表面的なパターンマッチングに過ぎない可能性がある [9] という指摘も複数あります。
Mumonはこの限界を認識したうえで、ToM推論を専用エージェント内に隔離し、その出力の信頼度を明示的にスコアリングする設計を採用しています。信頼度が低い場合、生成層は推定意図に過度に依存せず、より安全な応答戦略、すなわち傾聴寄りの振る舞いにフォールバックします。
過信を防ぎ、誤った意図推定が不適切な応答を生むリスクを構造的に低減するためです。感情の温度を読み、意図を推論し、その結果を応答生成の前提条件として注入する。
この一連のプロセスが、
「共感っぽい言葉を並べるAI」
「空気を読んで振る舞いを変えるMumon」
この2つのAIの決定的な違いを生みます。
ここで初めて、「空気を読む」は曖昧な比喩ではなく、アーキテクチャ上の能力として定義されます。
・・・・・
ただし、温度を読めるだけではまだ足りない場面があります。
Appraisal Agentが守るのは「感情の温度」です。しかし、次に問われるのはまったく別の問題です。ユーザーの感情的な圧力に流されず、事実を曲げないでいられるか。これは、温度を読む能力とは独立した、もう1つの構造的課題です。
次節では、「NOと言える自我」を設計する Boundary Audit Agent を見ていきます。