行動制御
Non-Directive Policy Agent:解決を急がず、傾聴に徹する力
早すぎる提案は、寄り添いではなく処理になる
前節の Boundary Audit Agent が守っていたのは、事実の防衛線でした。しかし、ブランド接客において難しいのは、「間違ったことを言わない」ことだけではありません。
もう1つ難しいのは、「まだ言うべきではないことを、言わない」ことです。
こんな場面を想像してみてください。見込み顧客がこう切り出したとする。
「植毛、気になってはいるんだけど、正直まだ踏み切れなくて......」
標準的な汎用LLMは、しばしばこう返します。
お気持ちはよくわかります。植毛は多くの方にとって大きな変化につながる選択肢です。 まずは無料カウンセリングで不安を整理してみませんか。実際に相談することで、 自分に合った選択肢が見えてくるかもしれません。
一見すると自然で、営業的にも正しく見えます。
しかしユーザーはここで、微かな圧迫感を覚えます。まだ自分の気持ちは整理されていないのに、会話がすでに次の行動へ進められているからです。
この違和感の正体は、提案の内容そのものではありません。提案のタイミングが早すぎるのです。
顧客接点では、情報不足が問題になる場面もあれば、むしろ感情の輪郭がまだ曖昧であること自体が問題になる場面もあります。人は、自分の迷いや不安を十分に言葉にする前に解決策を差し出されると、「助けられた」とは感じません。
「理解された」のではなく、「処理された」と感じるのです。
短期的には導線最適化に見えるかもしれません。
しかし長期で見れば、この感覚は反発や不信感を生み、AIを「押し売りをする存在」に変えてしまいます。ブランド好意、再訪率、継続利用、LTVにまで静かに影響していきます。
支援には段階がある。汎用LLMはその段階を飛ばしやすい
この問題は印象論ではありません。
感情支援対話の研究では、効果的な支援は一般に、複数段階をまたいで進行すると整理されています [10]。
- Exploration:まず相手の状況と感情を探索する
- Comforting:共感と理解を示して安心感を与える
- Action:具体的な行動を提案する
重要なのは、「助けようとすること」自体が問題なのではないという点です。問題は「いま相手がどの段階にいるのか」を見誤ったまま、Action を早出ししてしまうことにあります。
実際、汎用LLMは特定の支援戦略に偏りやすく、この偏りが高いほど低品質な応答が増えることが報告されています [11]。別の研究では、支援戦略を先に整える planner を挿入することで、低品質な応答が有意に減少しました [11]。つまり、応答の質を左右しているのは、助言の巧拙だけではなく、「どの段階で何を出すべきか」を外しやすいことなのです。
たとえば、見込み顧客が「最近ちょっと肌荒れがひどくて......」と切り出した直後に、「おすすめの施術はこちらです」と返す。
これは、Exploration を飛ばして Action に直行している状態です。相手がまだ自分の悩みの輪郭すら掴めていない段階で、解決策だけが先に到着してしまっている。
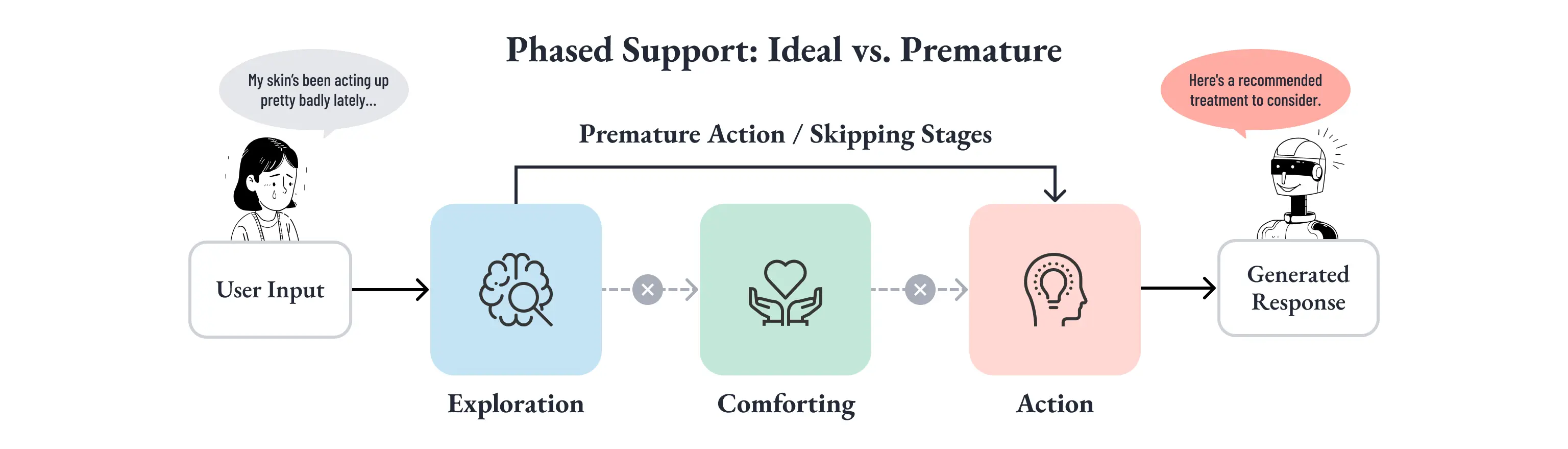
前半で整理した「過剰提案」は、営業トーンの問題ではありません。
支援段階の誤判定として捉え直すべき、構造的な課題です。
「待つ」は空白ではなく、能動的な抑制である
では、なぜ「待つ」ことがそれほど重要なのか。
Rogers の来談者中心療法は、変化は専門家が答えを与えた瞬間に起きるのではなく、本人が自分自身の感情を安全に探索できたときに起きると考えました [37][38]。Rosenberg の NVC もまた、観察と評価を分離し、相手の状態をすぐに助言や解釈へ変換しないことを核心原則に置いています [39]。
ここで支えられているのは、「正しい助言」ではありません。
「自分の気持ちを、自分の言葉で捉え直せる空間」です。
人は、まだ名前のついていない迷いを持っています。
不安なのか、怖いのか、期待しているのか、後ろめたいのか。自分でもまだ、はっきりわからない。そうした状態に対して、AIが先回りして答えや意味づけを与えてしまうと、その人は自分自身の気持ちにたどり着く前に、外から処理されてしまいます。
したがって傾聴とは、何もしない空白ではありません。
それは、解決策へ飛びつきたい衝動を抑え、相手がまだ名前を持っていない感情に留まることを許す、能動的な抑制です。
Non-Directive Policy Agent が守る価値は、「提案しないこと」ではありません。
「まだ結論にしない自由」です。
Helpful の衝動は、「待つ」を最も苦手とする
しかし標準的な汎用LLMにとって、この非指示性はきわめて不自然です。
Miller & Rollnick は、相手の問題を見た瞬間に、善意から解決策を先に提示してしまう反応を「Righting Reflex」と呼びました [40]。
- 友人が「最近、仕事がつらくて......」と漏らすと、「転職サイト見てみたら」とつい言ってしまう
- 医師が患者の話を最後まで聞く前に、処方や助言へ向かってしまう
- 親が子どもの悩みを聞いた瞬間に、「こうすればいいじゃない」と口を挟んでしまう
相手を助けたい。正したい。良くしたい。この善意の衝動そのものが、傾聴を難しくするのです。
汎用LLMにおいて、この問題はさらに構造的です。
標準的なモデルは、広く「役に立つこと」を強く報酬されるため、何もしない、結論を急がない、沈黙に近い応答に留まる、といった振る舞いを最も苦手とします [12][13]。モデルの内部から見れば、傾聴に徹することは「未完了」に近い。
提案する。
要約する。
次のアクションを示す。
そうしたほうが、成功として学習されやすいからです。
だから、プロンプトで「押しつけるな」と書くだけでは足りません。
善意のまま、過干渉へ滑っていくからです。
言い換えれば、汎用LLMにとって本当に難しいのは、「役に立たないこと」ではありません。「役に立とうとする衝動を、いったん抑えること」です。
導線を差し込む前に、心の段階を見極める
Non-Directive Policy Agent は、この Helpful の衝動に対する抑制ゲートとして実装されます。
Appraisal Agent や Boundary Audit Agent と同様に、このエージェントもまた、応答生成とは独立したLLM呼び出しとして先行動作します。
役割は明快です。
いま相手が、解決を求めているのか。それとも、まだ感情の整理や探索の段階にいるのか。これを、応答生成の前に判定するのです。
具体的に検出するのは、たとえば次のようなパターンです。
- 明示的な相談がない段階での解決策提示
- 心理的準備が整う前の予約導線・購入導線の差し込み
- 「こうすべきです」「まずはこれをしましょう」といった指示的表現
- 感情が十分に受け止められる前の過早なリフレーミング
こうしたパターンを検出した場合、Non-Directive Policy Agent は Shallow Solution Suppression シグナルを発行します。
ここで重要なのは、このシグナルが「助言を禁止するルール」ではないという点です。
後段の統合生成層が受け取るのは、「この段階ではまだ受容を優先する」という前提条件です。つまり、提案そのものを否定しているのではなく、提案を差し込む時機を誤らないようにしているのです。
同じ例を見てみましょう。
- 見込み顧客:「植毛、気になってはいるんだけど、正直まだ踏み切れなくて......」
- 従来のAI:「お気持ちはよくわかります。まずは無料カウンセリングで不安を整理してみませんか」
- Mumon:「そっか。気になってはいるけれど、まだ気持ちは固まりきっていないんだね」
後者は、何もしていないように見えるかもしれません。
しかし実際には、最も難しい制御を行っています。会話を成約モードへ早送りせず、ユーザーの心がまだ名前を持っていない状態に留まることを許しているからです。
否定しているのは導線ではなく、「準備が整う前の早出し」である
ここで重要なのは、Non-Directive Policy Agent が販売導線そのものを否定しているわけではないという点です。否定しているのは、「準備が整っていない相手に対して、善意の名のもとに導線を早出しすること」です。
行動提案は必要です。
しかしそれは、相手の不安が十分に言語化され、判断の主体性が保たれたあとに初めて、信頼ある提案として機能します。
短期的には、早い提案のほうが効率的に見えるかもしれません。
しかし長期で見ると、それはブランド好意、再訪率、継続利用、LTVを削ります。顧客が求めているのは、「すぐ動かしてくれるAI」ではなく、「自分のペースを侵食せずに、ちゃんとわかろうとしてくれるAI」だからです。
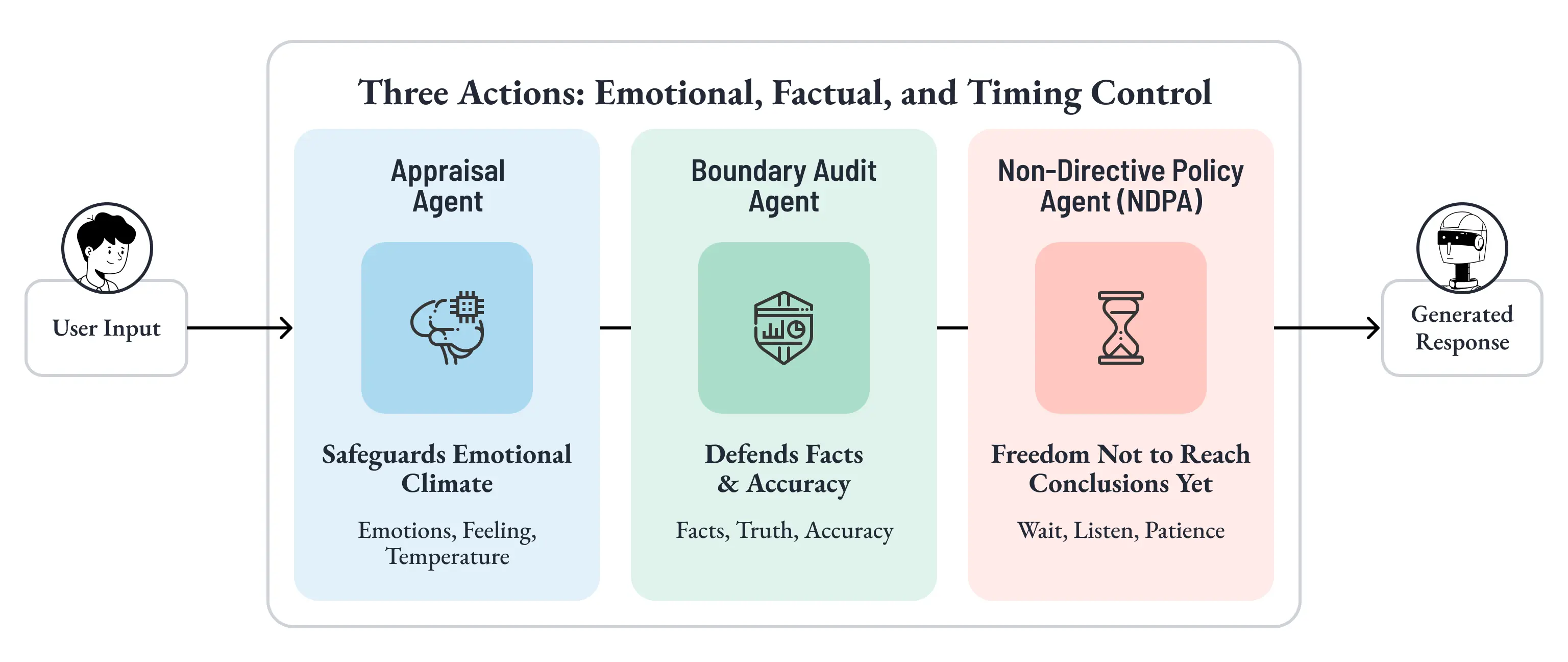
前節までを振り返ると、Appraisal Agent が守るのは「感情の温度」でした。Boundary Audit Agent が守るのは「事実の防衛線」でした。
そして Non-Directive Policy Agent が守るのは、そのどちらとも異なる、もう1つの重要な価値です。
それは、「まだ結論にしない自由」です。
何かを言い足すことより、言いすぎないこと。 進めることより、待つこと。
この難しい選択を、プロンプト上の願望ではなく、独立した制御として実装する。それによって初めて、Mumon は「解決を急がず、傾聴に徹するAI」になります。
・・・・・
これで、行動制御層の3つの判断軸が出そろいました。
しかし実際の顧客接点では、感情の温度があり、事実を曲げさせる圧力があり、まだ提案すべきでない心理段階がある。これらは順番にではなく、ほとんど常に、ひとつの入力の中に重なって現れます。
次に問われるのは、この3つをどう並列に走らせ、互いに競合させず、生成前の前提条件として安定化するかです。
次節では、この並列構成がなぜ制御を安定させるのかを整理します。