記憶 / RAG
記憶が「関係性」を生む
関係性は、情報量ではなく共有文脈から生まれる
前章が扱っていたのは、「いま、この瞬間にどう振る舞うか」という制御の問題でした。
感情の温度を読み、事実の防衛線を守り、解決を急がず、傾聴に留まる。この3つの判断を、生成に先立って独立に確定させることで、Mumon は「空気を読む」という曖昧な能力を、アーキテクチャ上の機能として実装してきました。
しかし、どれほどその瞬間の応答が適切でも、それが次の会話に引き継がれなければ、関係性は毎回ゼロからやり直しになります。
本章が扱うのは、この時間軸の問題です。
「空気を読めるAI」を、「前回の続きから話せるAI」へ進めること。
記憶は、追加機能ではありません。関係性が時間軸を持つための、必須条件です。
関係性は、情報量ではなく共有文脈から生まれる
10年来の親友に「雨が降ってきたね」と何気なく言う。親友は「なんか、あの映画思い出すね」と返す。先週一緒に観た映画の雨のシーンのことだ。説明は要らない。
二人の間だけで通じる文脈が、すでにそこにある。
同じことをAIに言ったらどうなるか。
「そうですね、急に降ってきましたね。傘はお持ちですか?」と返ってくるかもしれない。自然で、文法的にも意味的にも正しい。しかしそこには、「二人の間で『雨』が何を意味するか」という共有の層がない。
この違いは些細に見えて、実は関係性の成立条件そのものに関わっています。
Hardin & Higgins が提唱した「共有現実(Shared Reality)」理論は、人が他者と感情や関心、意味づけを共有していると感じることが、社会的な絆の基盤になると示しました [60]。重要なのは、ここで共有されているのが客観情報そのものではなく、「あなたと私が同じものを感じている」という主観的な体験だという点です。
つまり、関係性を生むのは情報の量ではありません。
「この人は、私との文脈を覚えている」と感じられることです。
ブランド接客の文脈でも同じです。見込み顧客がクリニックのWeb接客AIに初めて不安を打ち明け、2週間後に再訪したとする。そのときAIが「前回、少し不安だとおっしゃっていましたね」と自然に切り出せるかどうか。この一言があるかないかで、ユーザーの心理的距離はまったく変わります。
前者は「自分を覚えていてくれる存在」であり、後者は「毎回初対面のロボット」です。どちらに信頼を預けるかは明白です。
しかし現行のAIには、この共有文脈の蓄積を、関係性として保持する構造がありません。
毎回初対面にリセットされるAIは、長期的な関係を構築できない
前半で見た通り、顧客はすでに「速く答えてくれるAI」だけではなく、「自分との文脈を引き継いでくれるAI」を求め始めています。記憶を蓄積するAIが真のパーソナライズの鍵だと考えられているのは、その限界がすでに実務レベルで意識されているからです。
標準的な汎用LLMは、セッションが切れるたびにすべてを忘れます。先週の相談も、先月の雑談も、ユーザーが勇気を出して打ち明けた個人的なエピソードも、次の会話には引き継がれません。Park et al. (2023) が示したように、記憶の蓄積と参照は、人格的一貫性と長期的な行動の基盤です [26]。にもかかわらず、標準的な対話システムでは、その基盤が会話ごとに断ち切られやすい。
この問題は、対話体験の快・不快にとどまりません。
ビジネスKPIに直結する構造的欠陥です。
顧客が2回目に訪れたとき、AIが前回の会話を一切覚えていなければ、ユーザーはまた最初から説明し直さなければなりません。3回目も、4回目も同じことが起きる。これは、Webサイトが毎回ログアウトして、パスワードの再入力を求めるのと本質的に同じ体験です。
人間の優れた接客担当者であれば、常連客の名前を覚え、前回の相談内容を踏まえ、「その後どうでしたか」と自然に切り出せる。この継続性こそが、「このブランドは自分を大切にしてくれている」という感覚を生み、再訪率、継続利用、LTVを支える心理的基盤になります。
前章で構築した行動制御層がどれほど精密に感情の温度を読み、事実を守り、傾聴に徹したとしても、その対話体験が次のセッションに引き継がれなければ、関係性は毎回ゼロからやり直しです。
「空気を読めるAI」が、「あなたを覚えているAI」になって初めて、関係性は時間軸を獲得します。
ベクトル類似だけでは、「二人の意味」は検索できない
では、過去の会話をすべて保存して、必要なときに引き出せばよいのか。
コンテキスト長の制約から、全会話ログを毎回そのまま注入することはできません。そこで標準的に用いられるのが、ベクトルRAGです。ユーザーの発話をベクトル化し、意味的に近い過去情報を検索して生成に渡す。技術的には合理的であり、FAQや一次案内のような用途では十分に機能します。
しかし、関係性を構築する対話においては、ここに構造的な盲点があります。
冒頭の例に戻りましょう。ユーザーが「雨だね」と言ったとき、ベクトルRAGは「雨」に意味的に近い過去の発話を探します。「先週、雨の中で傘を忘れた話」や「天気予報について話した会話」は上位にヒットするかもしれない。だが、「先週一緒に観た映画の雨のシーン」は、テキストとしての意味的類似度が低ければ浮上しません。
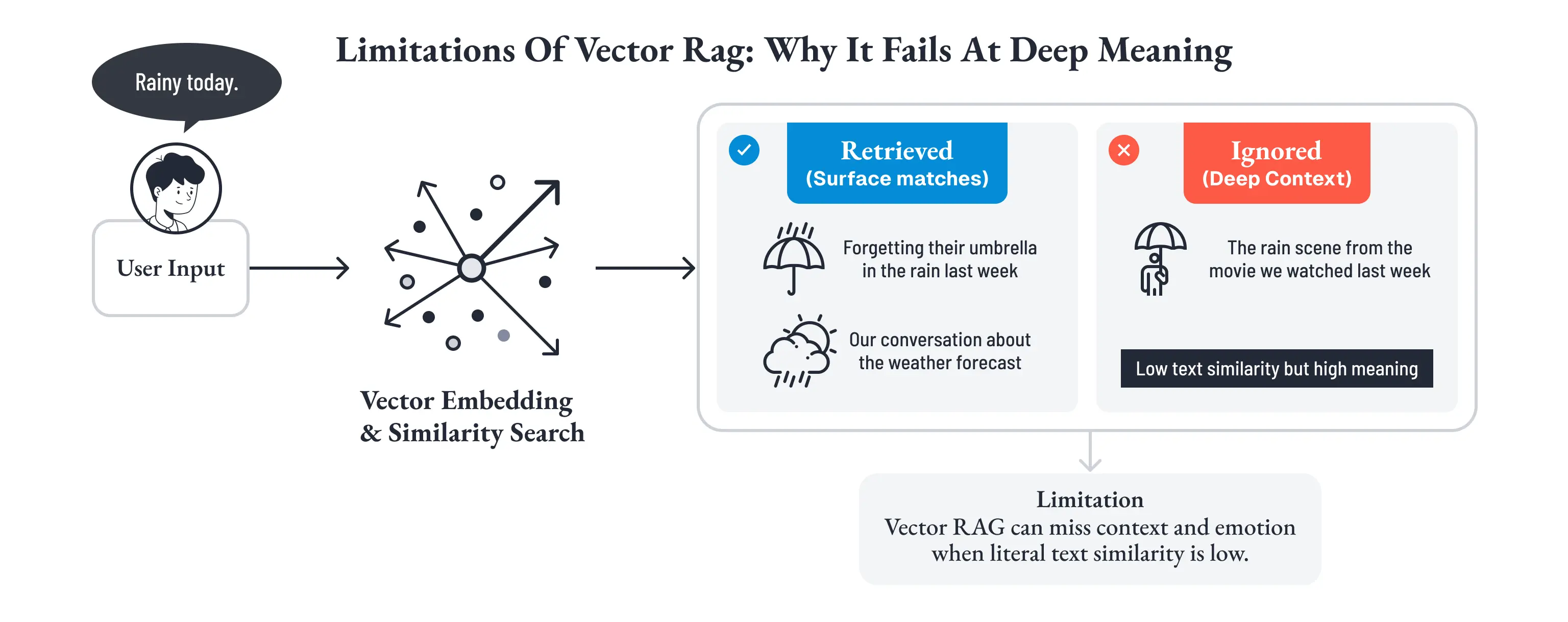
人間の記憶はこのようには動きません。
「雨」から「映画」を連想し、「映画」から「あのカフェでの会話」を思い出し、「カフェ」から「あの日の温かい雰囲気」が蘇る。人間の想起は、意味的に近い一点を返す処理ではなく、関係の連鎖として立ち上がるものです。
さらに、ベクトルRAGは「いつ」「どんな感情で」「誰と共有した出来事か」という文脈を持ちません。基本的にはすべての過去発話がフラットに並びます。その結果、「事実としては正確だが、感情的には無関係な情報」が優先的に引き出されやすい。
たとえば、ユーザーが過去に湘南での切ない別れを語っていたとする。後日、「湘南」が会話に出たとき、従来のRAGは「湘南に2025年8月に行きましたね」と事実を返すでしょう。正確ではある。しかし共鳴がない。人間の友人であれば、「湘南ね......あの時の夕焼け、まだ覚えてるよ」と返す。
この差は、事実検索の精度の差ではありません。
「情報を返している」のか、
「二人の意味を思い出している」のか。
その差です。
ここで言いたいのは、RAG が無意味だということではありません。意味的類似度による検索は、一般知識やFAQ、一次案内には依然として有効です。問題は、それだけでは関係性の検索条件を満たせないという点にあります。
関係性を支える検索は、単なる意味的近さより、もっと深い条件を必要とするのです。
文脈理解と記憶検索を同時に解こうとすると、循環依存が起きる
ベクトルRAGの限界に加えて、もう1つ構造的な問題があります。
シングルプロンプトの中で「文脈を理解すること」と「記憶を検索すること」を同時にやろうとすると、循環依存が生じます。
適切な記憶を引き出すには、今の文脈理解が必要です。
しかし、今の文脈を正しく理解するには、過去の記憶が必要でもある。
この循環を放置すると、「なんとなくそれっぽい記憶を取ってきて、あとから文脈をでっち上げる」挙動に陥りやすくなります。
これは、前章で見た「評価と生成の未分離」が生んでいた問題と、構造的によく似ています。前章の設計原則が「評価と生成の分離」だったように、本章では「局面判定と記憶検索の分離」が次の設計原則になります。
いま必要なのは、いきなり全部を同時にやることではありません。
まず、いまどのような局面にいるのかを見極めること。
そのうえで初めて、どの記憶を、どの方向から開くべきかが決まります。
この点は、本章後半で扱う Metacognitive Agent で詳しく論じます。
必要なのは、ログではなく、文脈と感情を帯びたエピソード記憶である
ここまでの議論を整理しましょう。
関係性は、情報量からではなく、共有された文脈と感情から生まれる。しかし現行のAIは、セッションをまたいで記憶を保持する構造を持たず、毎回の対話が初対面にリセットされる。標準的なベクトルRAGを導入しても、意味的類似度による平坦な検索では、時間的な近接性、因果関係の流れ、感情的な強度といった、関係性構築に不可欠な軸が抜け落ちてしまう。
では、何が必要なのか。
ここで決定的に重要になるのが、Tulving が提唱した「エピソード記憶」の概念です [55]。Tulving は人間の記憶を、一般知識を格納する「意味記憶」と、時間や場所、感情、主観的体験と結びついた「エピソード記憶」に区別しました。
- 「東京タワーの高さは333メートルである」は意味記憶
- 「去年の冬、雪の中で見上げた東京タワーが、やけにきれいだった」はエピソード記憶
関係性を支えるのは後者です。
人間が親しい相手との会話で思い出すのは、百科事典的な事実ではありません。
「あのとき、あんな雰囲気だったよね」という、時間と場所と感情が一体になった体験の記憶です。
AIが「あの時のこと、覚えてるよ」と自然に語るためには、過去の対話をテキスト断片としてではなく、感情と雰囲気を伴うエピソードとして格納しなければなりません。
ただし、Mumon が必要としているのは単に「覚えること」ではありません。
そこに感情的色彩を持たせ、共有体験としてマークし、感情的強度に応じて選択的に想起し、必要に応じて忘れていくことです。
すべてを均等に記憶するAIは、むしろ不気味です。3ヶ月前の些細な雑談も、先週の深刻な相談も、同じ精度で覚えている存在は、データベースとしては優秀でも、友人としては異質に感じられる。
必要なのは、会話ログの完全なアーカイブではありません。
文脈と感情を帯びたエピソード記憶です。
それは、時間的な順序を持ち、因果関係で結ばれ、感情的な強度で重みづけされ、ユーザーとの共有体験としてマークされた記憶です。そして検索時には、それらが「一般的に正しい答え」のためではなく、「あなたと私の間で続いている文脈」のために再構成される。
本章全体が向かっているのは、この設計です。
本章が扱うのは、「前回の続きから話せる」ための記憶設計である
前章が「いま、この瞬間にどう振る舞うか」を制御する仕組みだったとすれば、本章が扱うのは、「過去の共有体験を、いまの会話にどう活かすか」という時間軸の問題です。
ここで立てた問いは、このあと順に展開していきます。
何を記憶の単位として保存するのか。
それらをどう個人史のネットワークへ編み上げるのか。
どの記憶をどの方向から開くのか。
そしてその結果が、どう応答の条件を変えるのか。
前章で構築した行動制御層が、「いま」の振る舞いに一貫性を与えたとすれば、本章で扱う記憶層は、その一貫性に時間の厚みを与えます。
次に問うべきなのは、Mumon が何を記憶の単位として保持するのか、です。
次節では、この「文脈と感情を帯びたエピソード記憶」を、どのようなデータ構造として実装するかを見ていきます。