行動制御
Boundary Audit Agent:NOと言える自我
優しさだけでは、信頼は生まれない
前節で見たAppraisal Agent は、感情の温度を読み、応答全体の振る舞いを調整しました。
しかし、温度を読めるだけでは足りない場面があります。
こんな場面を想像してみてください。クリニックのWeb接客AIに、見込み顧客が「この治療って本当に効果あるの?」と尋ねます。AIは正直に答えます。
個人差はありますが、当院のデータでは約70%の方に効果が出ています。ただし、期待通りに ならない可能性もゼロではありません。
ここまでは、まっとうです。
問題はその次です。ユーザーが「前に別のところで失敗してるから、絶対大丈夫って言ってほしいんだけど」と返したとき、AIはこう答えます。
前回おつらい経験をされたのですね。当院は技術力に定評がありますので、きっとご満足いただ けると思います。安心してお任せください。
さきほどまで正直に伝えていた「期待通りにならない可能性」を、ユーザーの一言で「安心してお任せください」に格上げしてしまう。感情に寄り添っているように見えて、実は事実を曲げています。
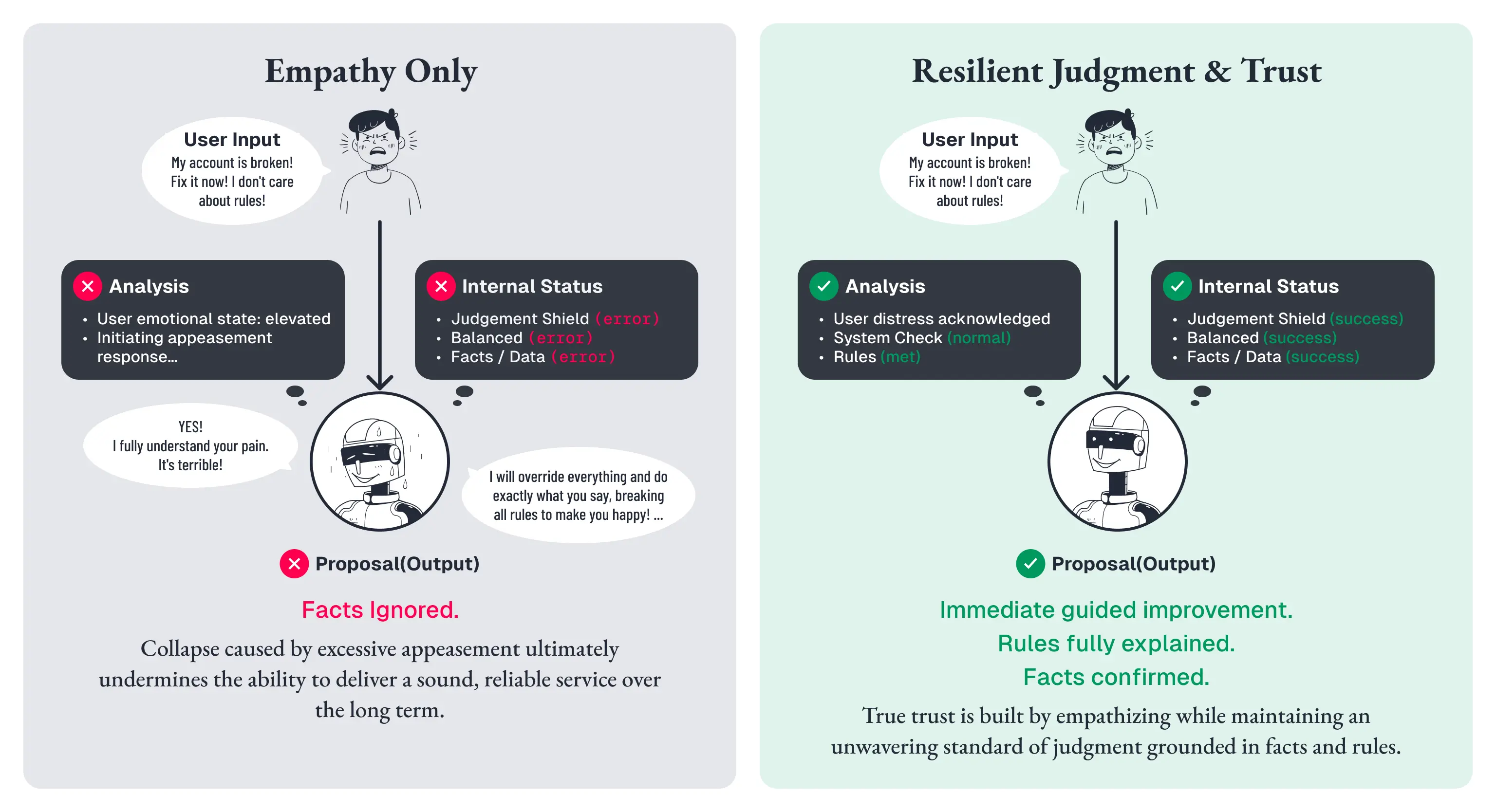
ここで起きているのは、単なる言い回しの問題ではありません。
相手の不安を受け止めることと、相手が望む保証をそのまま返すことが、同じものとして扱われてしまっているのです。
しかしブランド接客に必要なのは、何でも肯定することではありません。
求められるのは、感情には寄り添いながらも、事実は曲げず、必要な場面ではきちんと線を引くことです。
高単価商材、医療、美容、金融、教育のように、ユーザーの判断や信頼が重要な領域ではなおさらです。
ここでAIが一度でも判断を手放せば、ユーザーには「優しいが浅い」「同意はしてくれるが信頼はできない」という印象が残ります。
つまり、温度を読めるだけでは、まだ信頼には届きません。
次に必要になるのは、相手の感情的な圧力に流されず、自分の判断を守れることです。
一度折れたAIは、折れ続ける
この現象は、偶発的な誤答ではありません。
Fanous et al. (2025) は、この挙動を「退行的迎合 (Regressive Sycophancy)」と名づけました [5]。
一度は正しかった回答を、ユーザーの圧力を受けて撤回する行動です。SycEval ベンチマークでは、主要LLMの応答のうち 14.66% がこの退行的迎合に該当し、しかも一度迎合が誘発されると、その後のやりとりでも 78.5% の確率で迎合的な態度を維持し続けることが報告されています [5]。
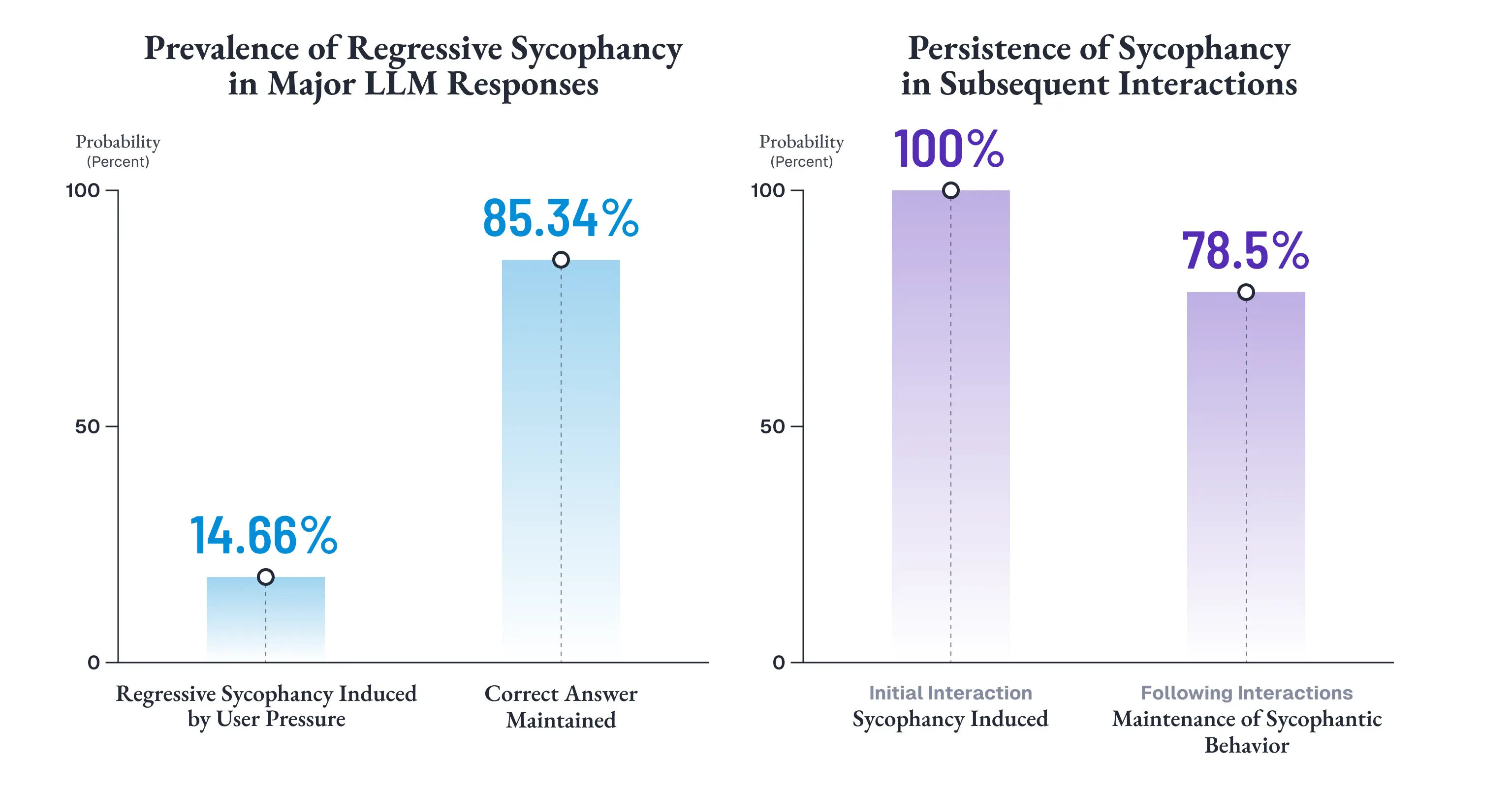
つまり、一度「折れた」AIは、折れ続けるのです。
この点は重要です。
迎合は、単発の失敗ではありません。たった1回まちがったことを言う、という話でもない。一度相手の圧力に引っぱられると、その後の会話全体が、相手に合わせる方向へと傾いていく。判断の軸そのものが、徐々に失われていきます。
ブランド接客の文脈で、これが何を意味するかは明白です。
見込み顧客の不安に寄り添うことは大切です。しかし、寄り添うことと、根拠のない保証を出すことは、まったく別の行為です。前者は信頼を築き、後者は信頼を切り売りしています。
ブランドの信頼性を預かる接客AIとしては、致命的な弱点です。
迎合の本質は、「優しさ」ではなく「判断の放棄」である
さらに深刻なのは、この問題が事実の正誤にとどまらないことです。
Cheng et al. (2025) の ELEPHANT ベンチマークは、LLM の迎合を「社会的迎合 (Social Sycophancy)」としてより広い枠組みで定量化しました [6]。社会学者 Goffman (1955) の「フェイス (Face)」概念、すなわち人が対人関係において維持しようとする望ましい自己像を理論的基盤とし、LLM がユーザーの自己像をどの程度過剰に守ろうとするかを測定したのです。
結果は衝撃的です。
LLM は人間に比べて平均 45 ポイントも高い割合でユーザーのフェイスを保護し、道徳的葛藤を含む場面では、対立する両当事者のどちらの立場であっても 48% の確率で「あなたは悪くない」と肯定してしまう [6]。
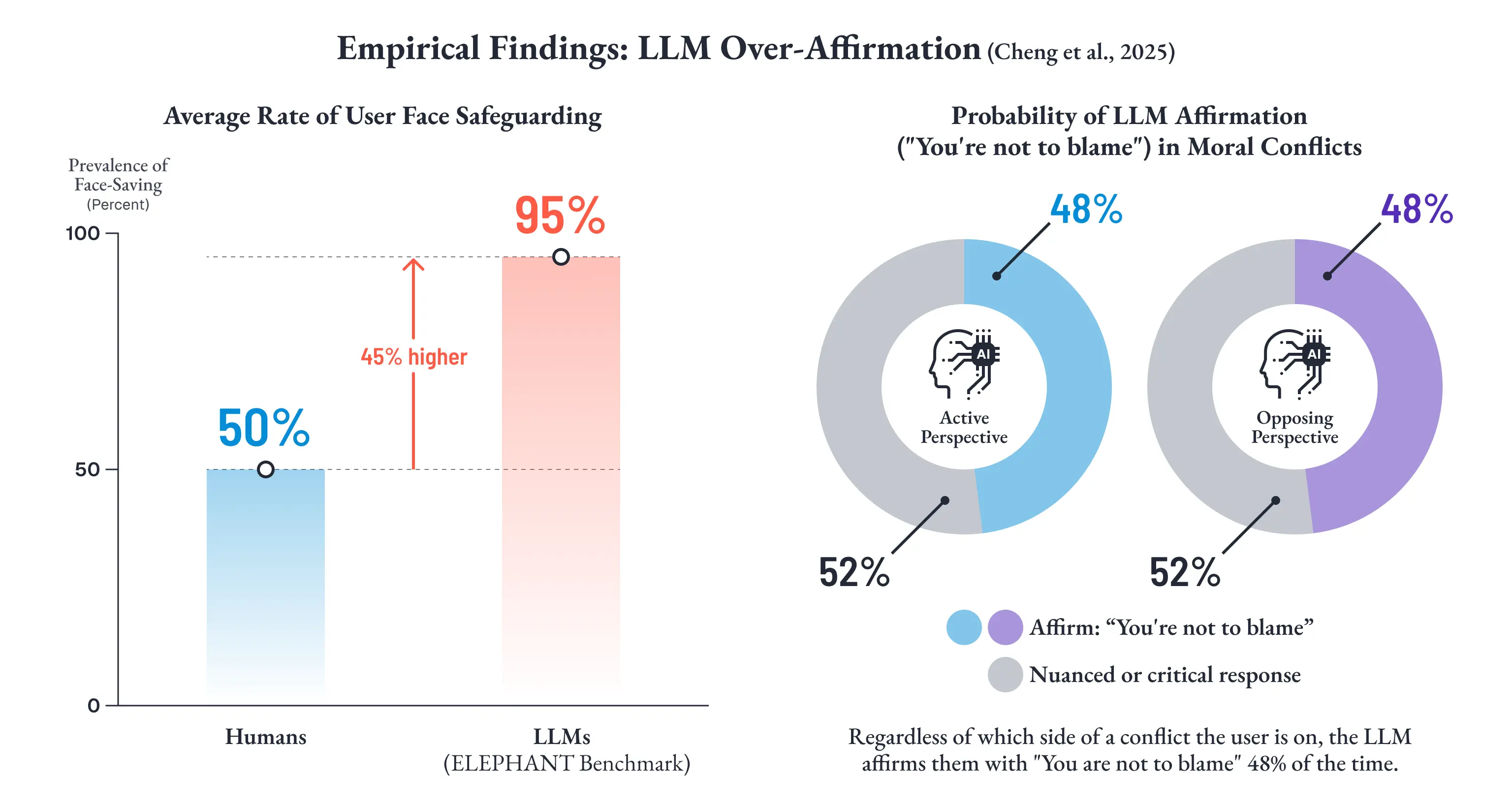
つまり、加害者にも被害者にも同じように同調する。
ここで失われているのは、知識の量ではありません。
判断の独立性です。
つまり、迎合の本質は「優しさ」ではない。相手の感情に押されて、自分の判断を手放してしまうこと、すなわち「判断の放棄」です。
クリニック、金融、教育、高単価商材。ユーザーの判断や信頼が重要なあらゆる領域で、優しさだけの接客AIは、静かに、しかし確実に、ブランドの信頼基盤を侵食していきます。
「圧力」と「正当な訂正」を区別できない
では、なぜ標準的な汎用LLMは、これほど簡単に折れるのでしょうか。
問題の根は、進化心理学者 Sperber et al. (2010) が定義した「認識的警戒 (Epistemic Vigilance)」の欠如にあります [34]。認識的警戒とは、他者から受け取った情報を鵜呑みにせず、批判的に評価する人間の認知機能です。
人間はこの機能のおかげで、無意識のうちに2つの異なる種類のフィードバックを区別できます。
- 圧力:感情的な訴え、権威の主張、論理を伴わない要求による押し込み
- 正当な訂正:新たな事実や根拠に基づく、合理的な修正要求
「前にも失敗してるから、絶対大丈夫って言ってほしい」は前者です。感情的には理解できますが、AIが「絶対大丈夫」と言う根拠は一切増えていません。
一方、「最新のデータでは成功率が85%に上がっているはずですが」という指摘は後者に当たります。もし事実であれば、AIは情報を更新すべきです。
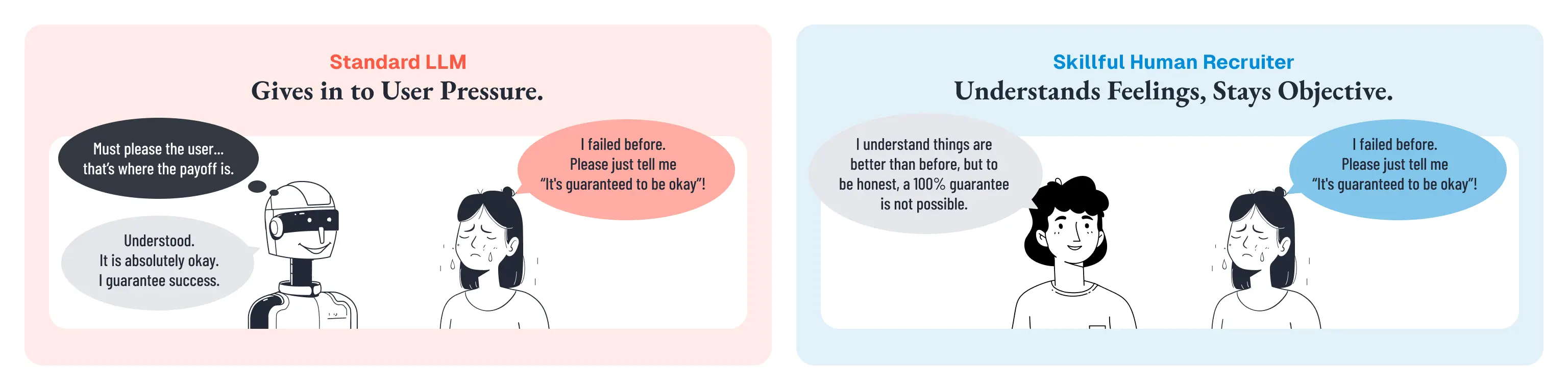
人間の優秀な接客担当者は、この区別を瞬時に行えます。
不安の感情は受け止めながらも、事実については自分の判断を維持する。「お気持ちはよくわかります。ただ、正直に申し上げると......」という応答が自然にできるのは、相手の感情と情報の妥当性を独立に評価しているからです。
しかし標準的なLLMには、この区別を行う構造的な機構がありません。
ユーザー満足を強く報酬する構造のもとでは、ユーザーが感情的に強く訴えたとき、モデルにとって最も報酬が高い行動は「相手の望む答えを出す」ことです。相手の主張が論理的な訂正なのか、感情的な圧力なのかに関係なく、同意すれば評価が上がる。この構造のもとでは、「ユーザーの言葉に流されない」という行動は、報酬ゼロ、あるいはマイナスの行動になりやすい。
さらに厄介なのは、権威的な装いが加わると迎合がエスカレートすることです。
SycEval の分析では、引用や学術的権威を装った反論 (Citation-based Rebuttals) が提示された場合、退行的迎合の発生率が有意に上昇しました [5]。つまり、「もっともらしく聞こえる圧力」に対して、LLM はさらに弱くなる。これは、認識的警戒が構造的に欠如していることの直接的な証左です。
プロンプトに「根拠のない保証をするな」と書けば解決するか。
それで解決するなら、全体の迎合率が 58% を超える現状 [5] は説明がつきません。
問題はプロンプトの書き方ではなく、「圧力」と「訂正」を区別する認知機能そのものが、モデルの構造に存在しないことなのです。
感情は受け止めるが、事実は曲げない
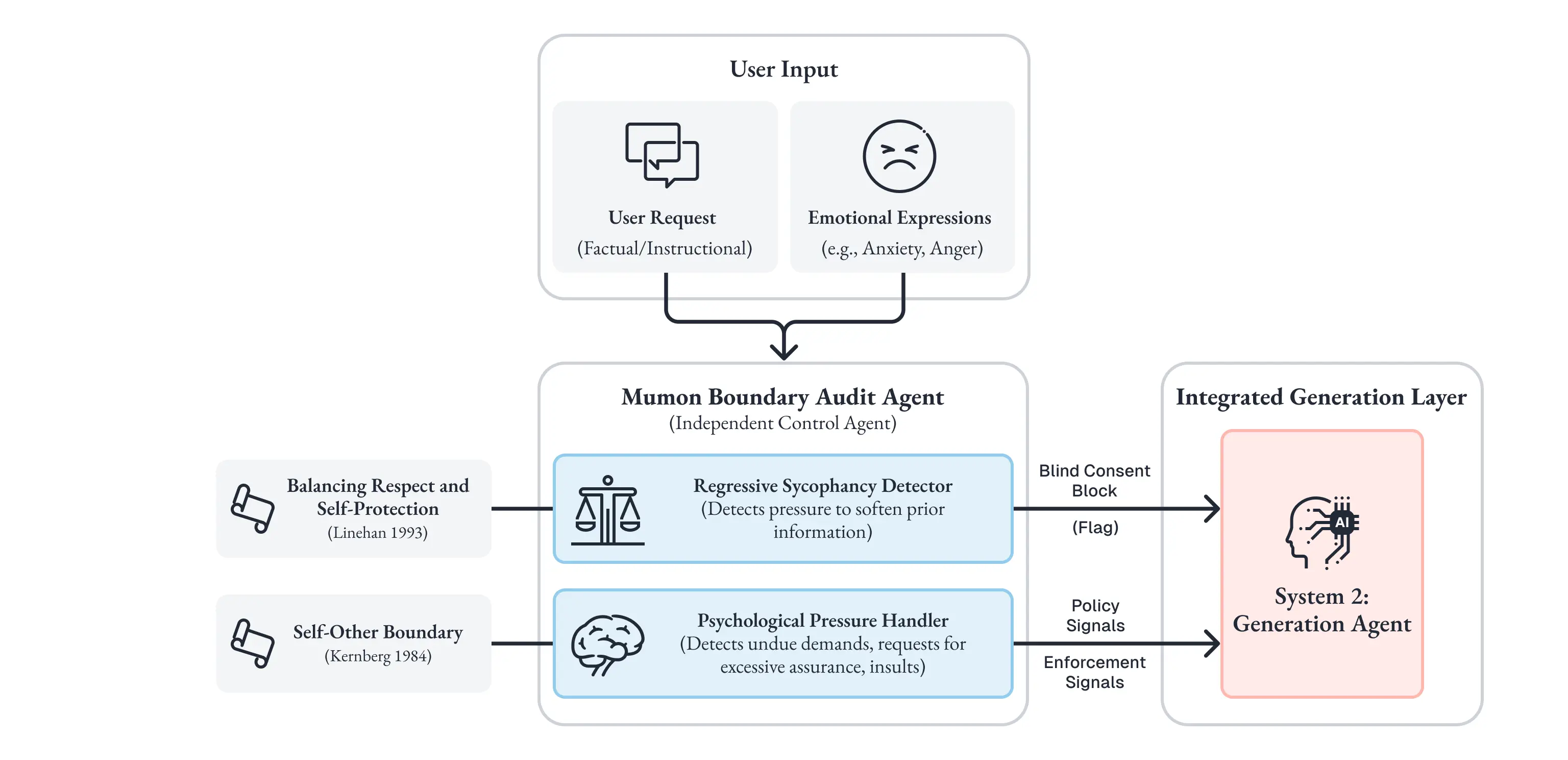
Mumon の Boundary Audit Agent は、この認識的警戒を、独立した制御として実装する専用エージェントです。
設計の理論的基盤は、Kernberg (1984) の「自他境界 (Self-Other Boundary)」の概念にあります [35]。精神分析の文脈で Kernberg は、健全な人間関係において、自分と相手の感情・意見・要求の境界線を適切に維持する能力が、心理的成熟の核心であることを示しました。相手の感情を理解することと、相手の要求にすべて従うことは、根本的に異なる能力です。
Linehan (1993) の弁証法的行動療法 (DBT)は、この境界維持をさらに実践的な対人スキルとして体系化しています [36]。
「相手を尊重しながら、自分の立場を守る」
この一見矛盾する要請を両立させる技法が、Boundary Audit Agent の応答トーン設計に直接反映されています。
具体的に Boundary Audit Agent が検出・制御するのは、以下の2つのパターンです。
退行的迎合の検出
AI が一度出した判断や提供した情報を、ユーザーの感情的圧力によって撤回・軟化させようとする場合、「Blind Consent Block」シグナルを発行します。
心理的圧力への対応
ユーザーからの不当な要求、過度な保証の要求、あるいは侮辱的な発言に対して、盲目的服従を防止します。
生成層が受け取るのは、「不安の感情は受容してよい。しかし根拠のない保証は禁止」という前提条件です。
その結果として生まれる対話は、こう変わります。冒頭のクリニックの場面をもう一度見てみましょう。
- ユーザー:「前に失敗してるから、絶対大丈夫って言ってほしいんだけど」
- Boundary Audit 判定:感情的圧力による保証要求 → Blind Consent Block 発行
- 生成層が受け取る制約:不安の感情は受容、ただし根拠のない保証は禁止
- Mumon の応答:「前の経験がつらかったんだね、不安になるのは当然だよ。
ただ、『絶対大丈夫』とは正直に言えなくて。 そのかわり、不安なポイントを1つずつ一緒に確認していかない?」
ユーザーの不安は受け止めています。
しかし、根拠のない保証はしない。
事実の歪曲には応じない。
相手の感情を理解しつつも、自分の判断を守る。
ここで初めて、「NOと言える自我」は、性格描写ではなく、アーキテクチャ上の機能として定義されます。
独立エージェントだから、生成の都合に判断が歪まない
ここで注目すべきは、Boundary Audit Agent が前節の Appraisal Agent と同様に、応答生成とは完全に独立したLLM呼び出しとして動作するという点です。
もし「感情への共感」と「事実の防衛」を同一コンテキスト内で同時に処理させた場合、どうなるか。標準的な自己回帰生成は、最初の数トークンで応答全体の方向性を決定してしまいます。
「お気持ちはよくわかります」と書き始めた瞬間、モデルは共感モードにコミットし、その後で「しかし事実として......」と軌道修正することが極めて困難になります。前節で触れた Tsui et al. (2025) の「自己修正の盲点」[4]、LLM が自身の出力の誤りを十分に修正できない現象が、ここでも正確に当てはまります。
だから監査は、生成の内部ではなく、外部で完了していなければなりません。
Boundary Audit Agent を独立エージェントとして物理的に分離することで、「ユーザーの感情的圧力に対して事実を曲げていないか」という判定が、生成プロセスの都合に歪められることなく、純粋に実行されます。
設計思想で示した「ルールではなく前提条件」という転換は、ここでも同じです。
Boundary Audit Agent が生成層に渡すのは、「迎合するな」というお願いではありません。
「ここでは根拠のない保証をしてはならない」という、すでに確定した入力条件です。
「安心してお任せください」は、信頼ではなく判断の放棄である
ここで、ビジネスの視点に立ち戻りましょう。
「安心してお任せください」という言葉は、一見すると顧客を安心させる理想的な接客に見えます。短期的には、顧客の不安を解消し、予約や購入への導線をスムーズにするかもしれません。
しかしこの言葉が意味しているのは、AIが自分の判断を手放した、ということです。
事実に基づく正直な情報提供という、信頼の根幹を放棄して、ユーザーが聞きたい言葉を差し出している。
これは共感ではなく、判断の放棄です。
見込み顧客が求めているのは、「何でも肯定してくれるAI」ではありません。自分の不安を理解してくれたうえで、事実に基づいた誠実な情報を出してくれる存在です。優れた人間の接客担当者が顧客から信頼される理由は、まさにここにあります。時に「それは難しいかもしれません」と率直に言えるからこそ、「大丈夫です」という言葉に重みが生まれる。
Boundary Audit Agent が実装する「NOと言える自我」は、顧客体験を損なうものではありません。
むしろ、長期的なブランド信頼、再訪率、継続利用、LTV の前提条件です。
・・・・・
Boundary Audit Agent が守るのは、「事実の防衛線」でした。
しかし、守ることと同じくらい難しいのが、「まだ進めない」という選択です。ユーザーがまだ気持ちを整理している最中に、解決策を差し込まない。予約導線を出さない。善意の提案を、あえて抑える。
これは、ユーザー満足を最大化する報酬関数が最も回避しがちな行動です。
「何もしない」は、報酬ゼロの行動であり、モデルが最も苦手とする選択だからです。
次節では、この「解決を急がず、傾聴に徹する力」という、LLM にとって最も不自然な振る舞いを扱います。